TensorRTとDeepStream SDKを使用してNVIDIA JetsonでYOLOv8を使用する
TensorRTとDeepStream SDKを使用してNVIDIA JetsonでYOLOv8を使用する
本Wikiでは、NVIDIA Jetsonプラットフォームへの学習済みAIモデルの読み込みと、TensorRTとDeepStream SDKを使用した推論の方法を説明します。TensorRTを使用することで、Jetsonプラットフォームでの推論パフォーマンスを最大限に利用できます。

システム要件
- UbuntuがインストールされたホストPC(Ubuntuネイティブ環境またはVMware Workstation Playerを使用したもの)
- reComputer Jetson、もしくはJetPack4.6以降が動作するその他のNVIDIA Jetsonデバイス
各JetPackのバージョンに対応するDeepStreamのバージョン
YOLOv8とDeepStreamを組み合わせて使用する際、SeeedではDeepStream-YOLOレポジトリの使用をおすすめします。対応するDeepStreamのバージョンはJetPackのバージョンごとに違います。正しいバージョンを選んで使用してください。
| DeepStreamのバージョン | JetPackのバージョン |
|---|---|
| 6.2 | 5.1.1 |
| 5.1 | |
| 6.1.1 | 5.0.2 |
| 6.1 | 5.0.1 DP |
| 6.0.1 | 4.6.3 |
| 4.6.2 | |
| 4.6.1 | |
| 6.0 | 4.6 |
本WikiではJetPack 5.1.1をインストールしたreComputer J4012上でDeepStream SDK 6.2を使用して検証を行なっています。
JetsonにJetPackをインストールする
CUDA、TensorRT、cuDNNなどのSDKコンポーネントを含むJetPackシステムがJetsonデバイスに書き込まれていることを確認してください。NVIDIA SDK Managerもしくはコマンドラインで書き込みが行えます。
SeeedのJetsonデバイスへの書き込みについては以下のリンクをご覧ください。
- reComputer J1010/J101
- reComputer J2021/J202
- reComputer J1020/A206
- reComputer J4012/J401
- A203 Carrier Board
- A205 Carrier Board
- Jetson Xavier AGX H01 Kit
- Jetson AGX Orin 32GB H01 Kit
DeepStreamのインストール
JetsonにDeepStreamをインストールする方法は複数あります。詳しくはこちらのガイドを参照してください。成功率が高く簡単なため、SeeedではSDK Managerを使用したDeepStreamのインストールを推奨しています。
SDK Managerを使用してDeepStreamをインストールした場合には、DeepStream用の追加設定のインストールのため、システム起動後に以下のコマンドの実行が必要です。
sudo apt install \
libssl1.1 \
libgstreamer1.0-0 \
gstreamer1.0-tools \
gstreamer1.0-plugins-good \
gstreamer1.0-plugins-bad \
gstreamer1.0-plugins-ugly \
gstreamer1.0-libav \
libgstreamer-plugins-base1.0-dev \
libgstrtspserver-1.0-0 \
libjansson4 \
libyaml-cpp-dev
必要パッケージのインストール
- Step 1. Jetsonデバイスのターミナルからpipのインストールとアップグレードを行います。
sudo apt update
sudo apt install -y python3-pip
pip3 install --upgrade pip
- Step 2. 以下のレポジトリをコピーします。
git clone https://github.com/ultralytics/ultralytics.git
- Step 3. requirements.txtを開きます。
cd ultralytics
vi requirements.txt
- Step 4. 以下の行の記述を変更します。編集モードに入るには最初にiキーを押します。ESCキーを押した後:wqで保存、終了します。
# torch>=1.7.0
# torchvision>=0.8.1
注 : この段階ではtorchとtorchvisionは含まれていません。後ほどインストールを行います。
- Step 5. 必要パッケージをインストールします。
pip3 install -r requirements.txt
インストール中にpython-deteutilパッケージのバージョンが古いというエラーが表示される場合は、以下のコードを実行してアップグレードを行なってください。
pip3 install python-dateutil –upgrade
PyTorchとTorchvisionのインストール
PyTorchやTorchvisionはJetsonプラットフォームなどARM aarch64アーキテクチャベースの製品上での動作には対応していないため、pipを使用してのインストールが不可能です。このため、プリビルドのPyTorch pip wheelを手動でインストールし、Torchvisionをソースからコンパイル/インストールする必要があります。
PyTorchとTorchvisionに関する全てのリンクはこちらのページをご覧ください。
以下ではJetPack 5.0以降でサポートされているバージョンについて説明します。
PyTorch v1.11.0
対応バージョン : JetPack 5.0(L4T R34.1.0) / JetPack 5.0.1 (L4T R34.1.1) / Python 3.8をインストールしたJetPack 5.0.2 (L4T R35.1.0)
ファイル名 : torch-1.11.0-cp38-cp38-linux_aarch64.whl
URL : https://nvidia.box.com/shared/static/ssf2v7pf5i245fk4i0q926hy4imzs2ph.whl
PyTorch v1.12.0
対応バージョン : JetPack 5.0 (L4T R34.1.0) / JetPack 5.0.1 (L4T R34.1.1) / Python 3.8をインストールしたJetPack 5.0.2 (L4T R35.1.0)
ファイル名 : torch-1.12.0a0+2c916ef.nv22.3-cp38-cp38-linux_aarch64.whl
URL : https://developer.download.nvidia.com/compute/redist/jp/v50/pytorch/torch-1.12.0a0+2c916ef.nv22.3-cp38-cp38-linux_aarch64.whl
- Step 1. 以下のフォーマットを使用して、お使いのJetPackのバージョンに対応したバージョンのTorchをインストールします。
wget <URL> -O <file_name>
pip3 install <file_name>
例えば、JetPack 5.0.2を使用している場合には以下のようにPyTorch v1.12.0をインストールします。
sudo apt-get install -y libopenblas-base libopenmpi-dev
wget https://developer.download.nvidia.com/compute/redist/jp/v50/pytorch/torch-1.12.0a0+2c916ef.nv22.3-cp38-cp38-linux_aarch64.whl -O torch-1.12.0a0+2c916ef.nv22.3-cp38-cp38-linux_aarch64.whl
pip3 install torch-1.12.0a0+2c916ef.nv22.3-cp38-cp38-linux_aarch64.whl
- Step 2.インストールしたPyTorchのバージョンに対応したバージョンのTorchvisionをインストールします。ここでは例として、上でインストールしたPyTorch v1.12.0に対応したTorchvision v0.13.0をインストールしています。
sudo apt install -y libjpeg-dev zlib1g-dev
git clone --branch v0.13.0 https://github.com/pytorch/vision torchvision
cd torchvision
python3 setup.py install –user
以下は各PyTorchのバージョンに対応するTorchvisionのバージョンです。
- PyTorch v1.11 - torchvision v0.12.0
- PyTorch v1.12 - torchvision v0.13.0
さらに詳細なリストはこちらのリンクをご覧ください。
YOLOv8を使用するためのDeepStreamの設定
- Step 1. 以下のリポジトリをコピーします。
cd ~
git clone https://github.com/marcoslucianops/DeepStream-Yolo
- Step 2. 以下のコマンドを実行します。
cd DeepStream-Yolo
git checkout 68f762d5bdeae7ac3458529bfe6fed72714336ca
- Step 3. DeepStream-Yolo_utils内のgen_wts_yoloV8.pyをUltralyticsディレクトリ内にコピーします。
cp utils/gen_wts_yoloV8.py ~/ultralytics
- Step 4. Ultralyticsリポジトリ内にリンク内のpt fileをダウンロードします。
wget https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8s.pt
注 : カスタムモデルも使用できますが、エンジンが正しく生成されるよう、cfgおよびweights/wtsのファイル名にはYOLOモデルのリファレンス(yolo8_)を含めてください。
- Step 5. cfg、wtsおよび(必要であれば)labels.txtファイルを生成します。以下のコードはYOLOv8用のものです。
python3 gen_wts_yoloV8.py -w yolov8s.pt
注 : 推論のサイズを変更するには以下のコードを使用してください。デフォルトでは640に設定されています。
-s SIZE
--size SIZE
-s HEIGHT WIDTH
--size HEIGHT WIDTH
Example for 1280:
-s 1280
or
-s 1280 1280
- Step 6. 生成されたcfg、wtsおよびlabels.txtファイルをDeepStream-Yoloフォルダに移動します。
cp yolov8s.cfg ~/DeepStream-Yolo
cp yolov8s.wts ~/DeepStream-Yolo
cp labels.txt ~/DeepStream-Yolo
- Step 7. DeepStream-Yoloフォルダを開いてライブラリのコンパイルを実行します。
cd ~/DeepStream-Yolo
CUDA_VER=11.4 make -C nvdsinfer_custom_impl_Yolo # for DeepStream 6.2/ 6.1.1 / 6.1
CUDA_VER=10.2 make -C nvdsinfer_custom_impl_Yolo # for DeepStream 6.0.1 / 6.0
- Step 8. 使用するモデルに合わせてconfig_infer_primary_yoloV8.txtファイルを編集します(以下は例としてYOLOv8sを80 classesで使用する場合のコードです)。
[property]
...
custom-network-config=yolov8s.cfg
model-file=yolov8s.wts
...
num-detected-classes=80
…
- Step 9. deepstream_app_config.txtファイルを編集します。
...
[primary-gie]
...
config-file=config_infer_primary_yoloV8.txt
- Step 10. deepstream_app_config.txtファイル内のビデオの参照元を変更します。デフォルトでは以下の場所に設定されています。
...
[source0]
...
uri=file:///opt/nvidia/deepstream/deepstream/samples/streams/sample_1080p_h264.mp4
推論の実行
deepstream-app -c deepstream_app_config.txt
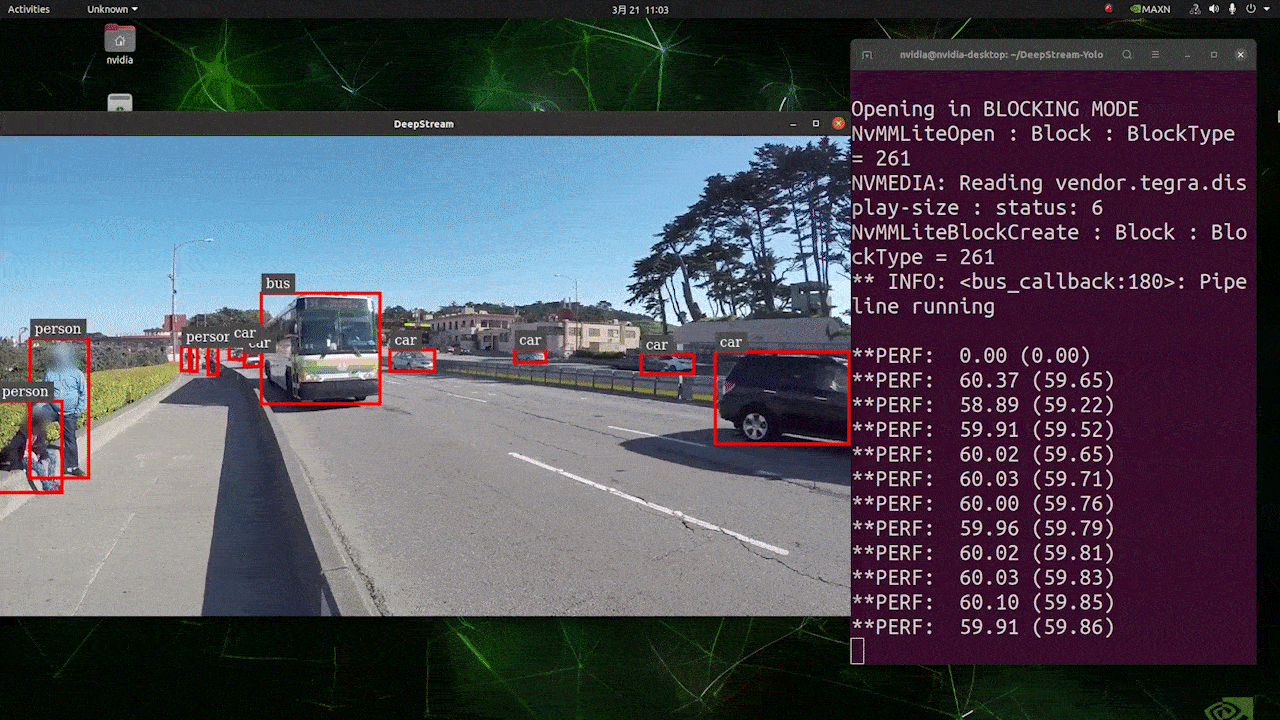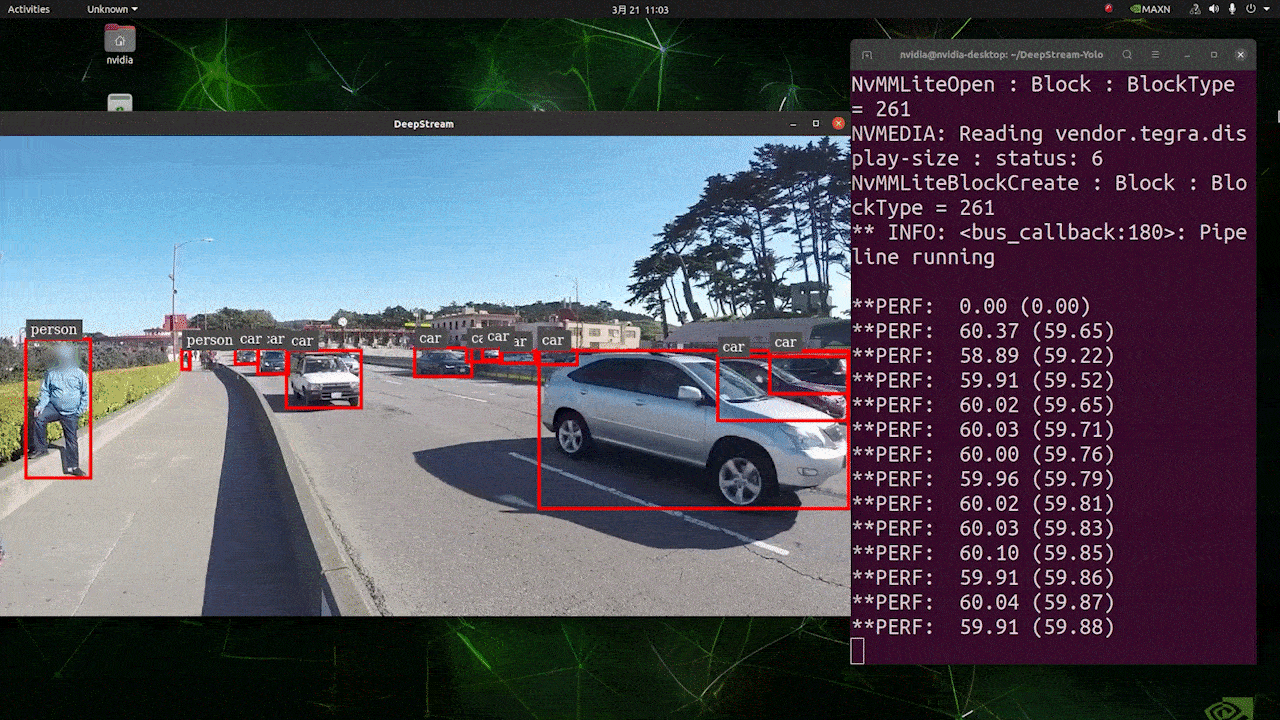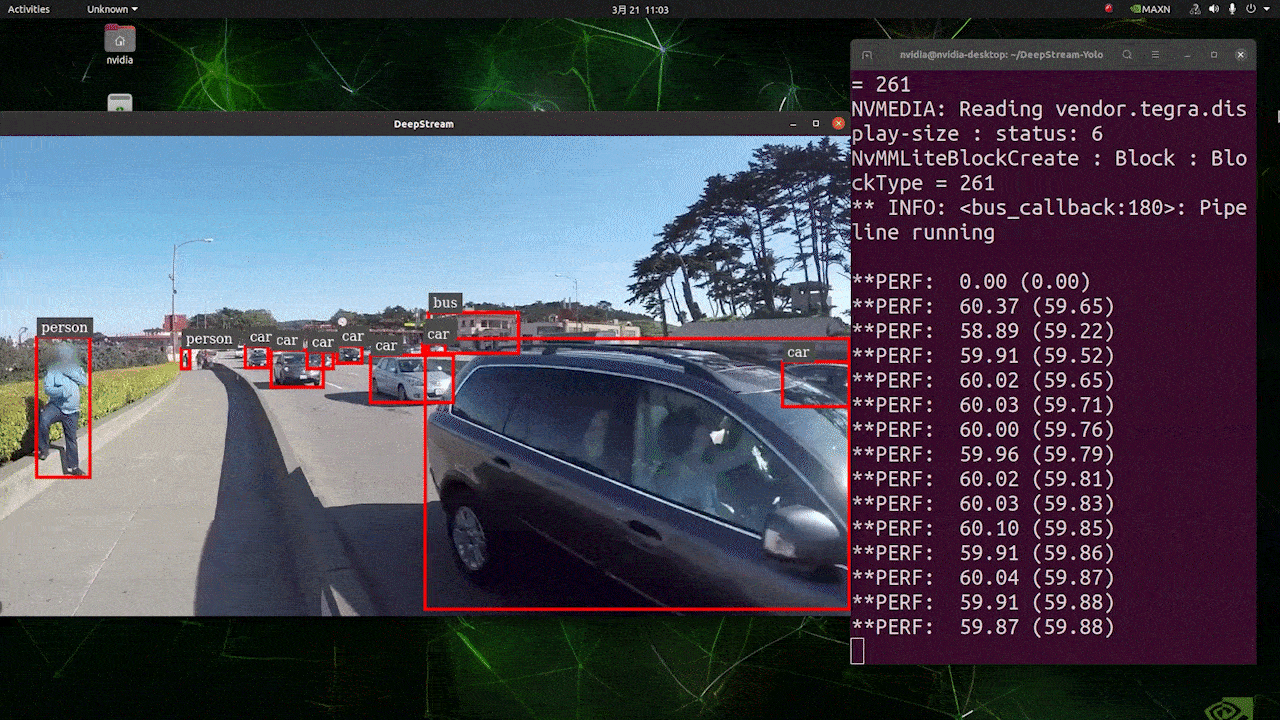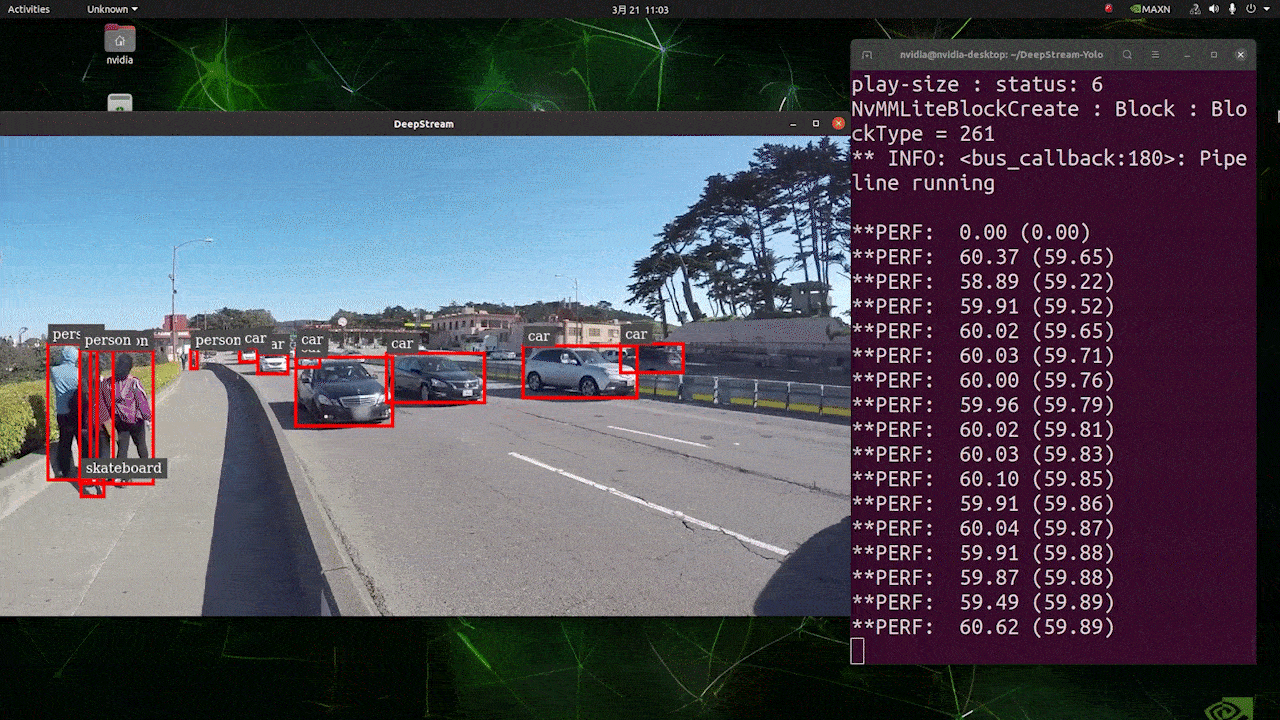
上はFP32及びYOLOv8s 640 x 640の設定でJetson AGX Orin32 GB H01 Kit上で推論を実行した場合の結果です。FPSは60の前後となっており、実際のFPSとは異なっています。これは、deepstream_app_config.txtファイル内の[sink0]がtype=2に設定されているためで、モニタのFPSによって制限を受けたり、このガイドを執筆するためにSeeedで使用しているモニタが60Hzモニタであるためです。 この値をtype=1に変更することで最大のFPSで実行が可能ですが、リアルタイムな検知結果の出力は不可能な可能性があります。
上で使用したのと同じビデオソースとモデルを使用し、[sink0]をtype=1に設定した場合の推論結果は以下のようになります。
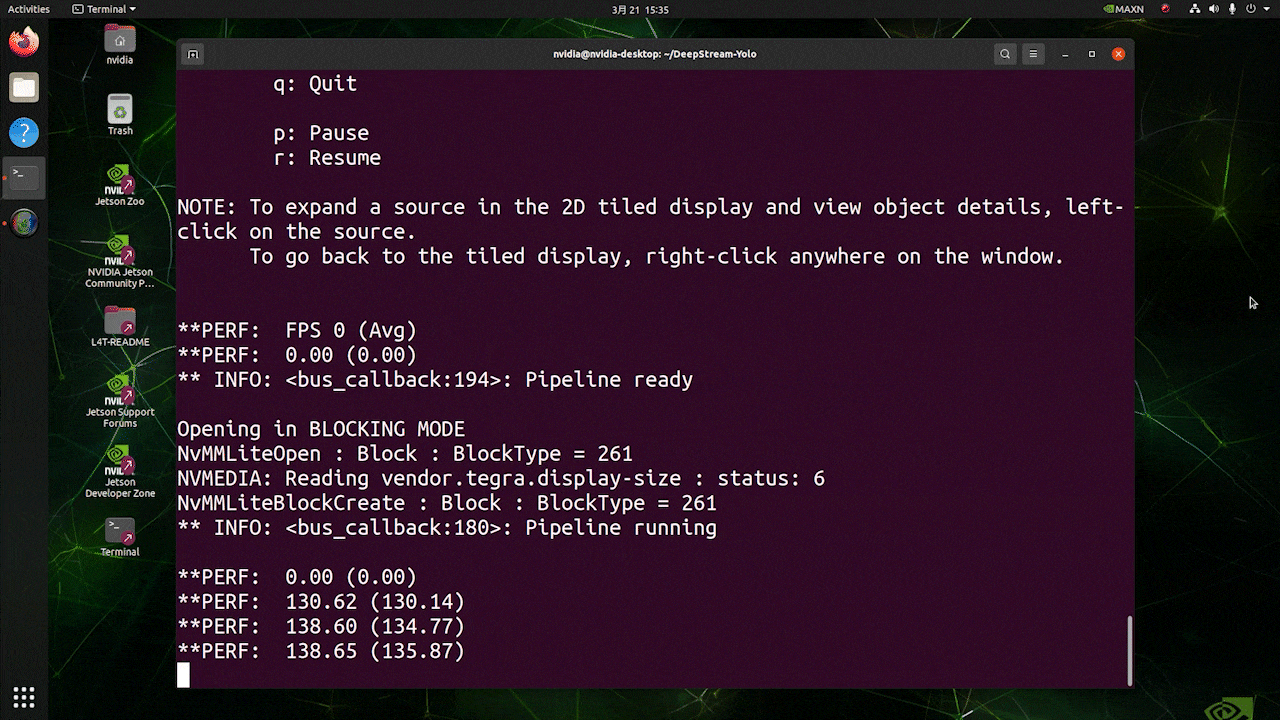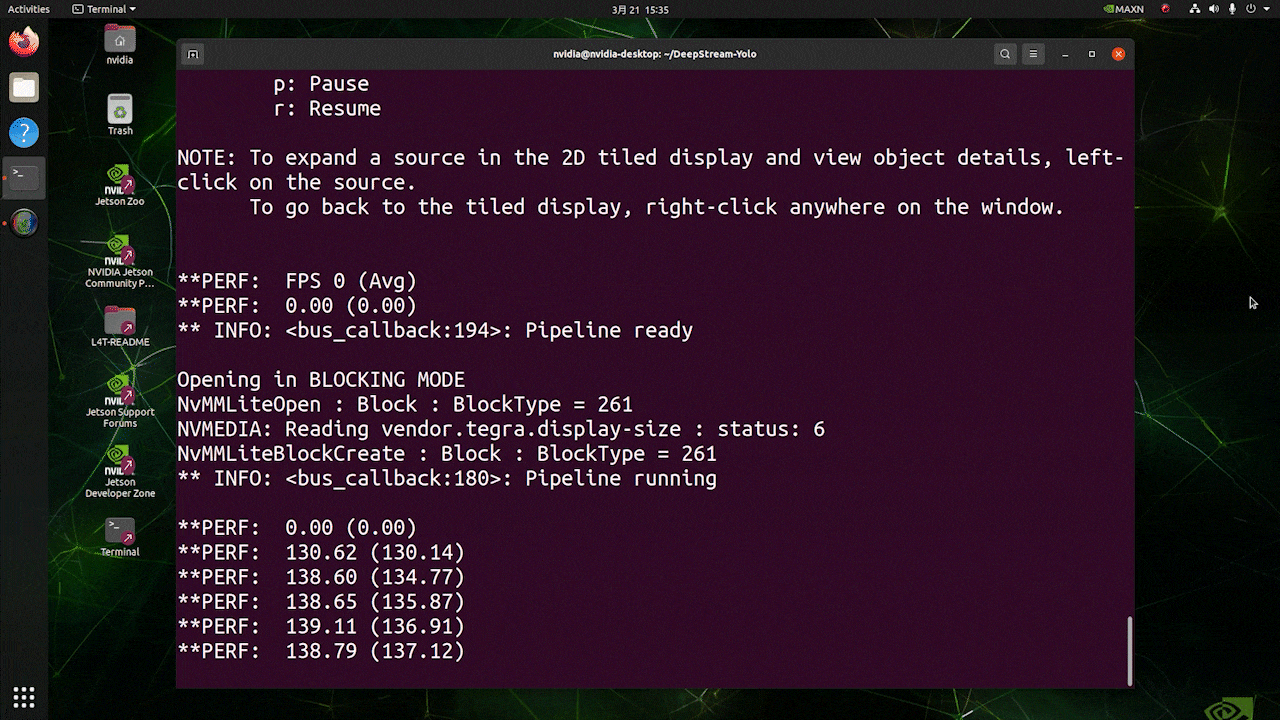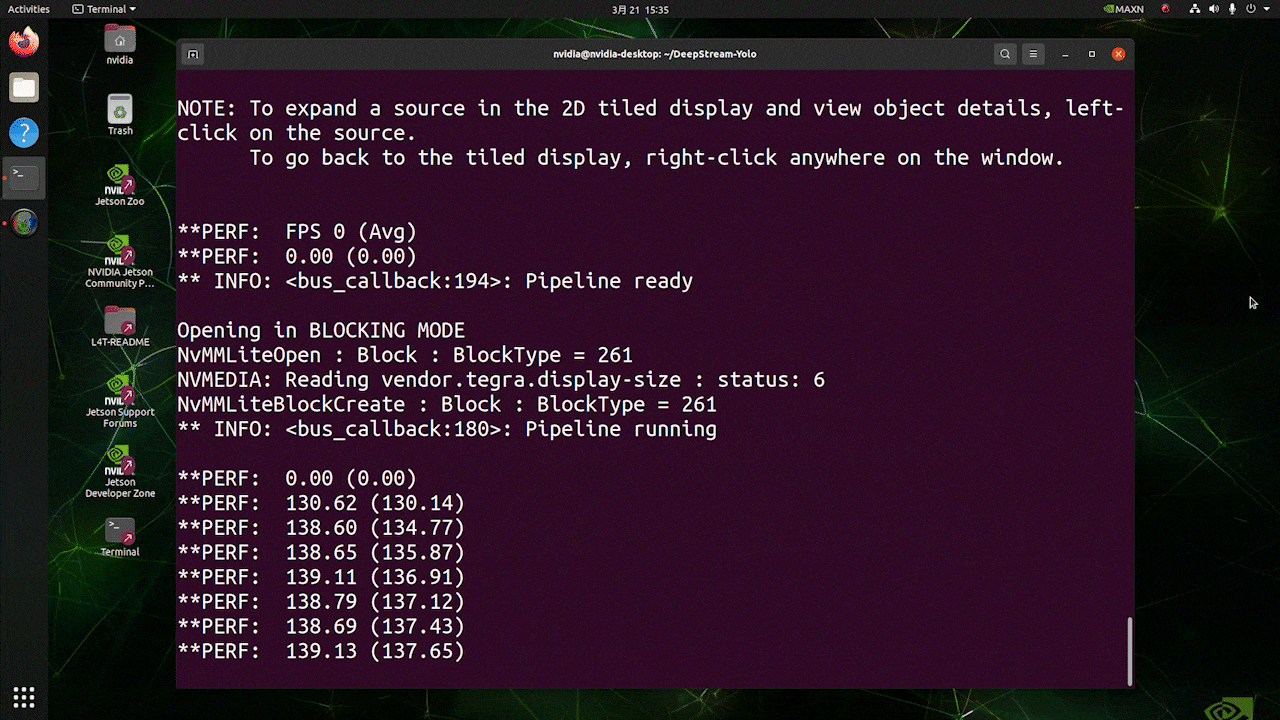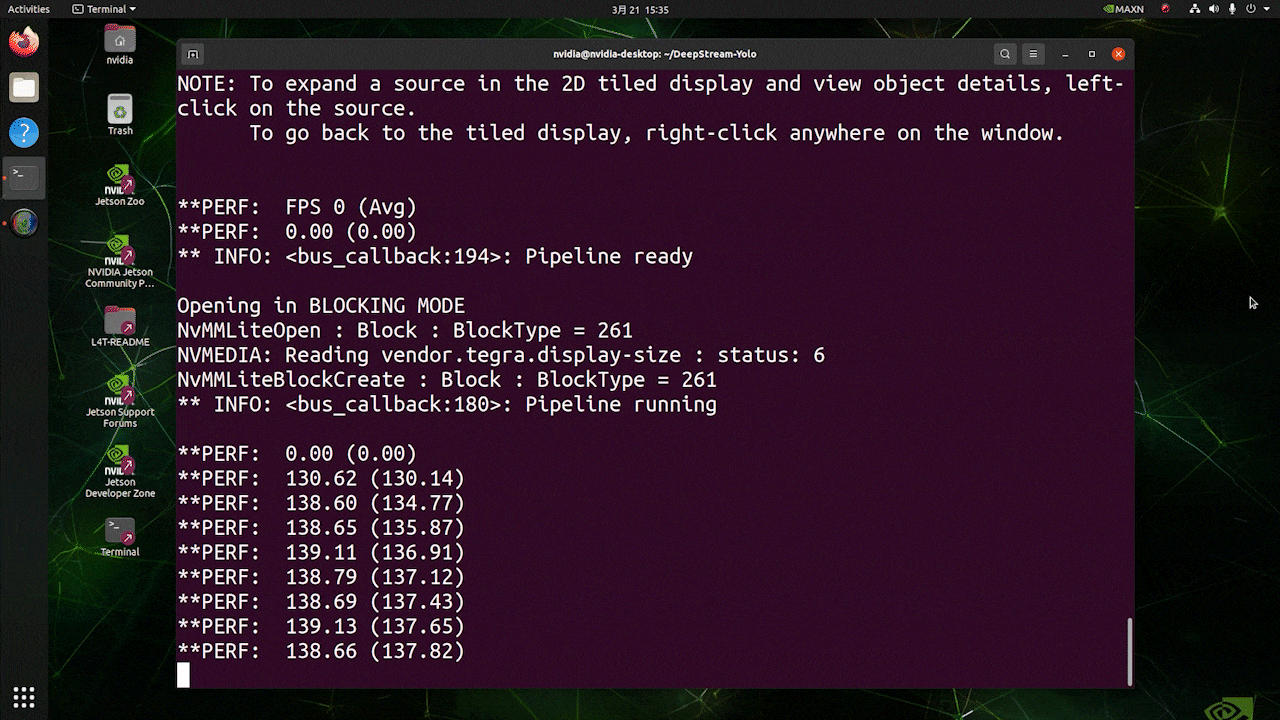
FPSは139前後と、実際のFPSの値が反映されています。
INT8キャリブレーション
INT8精度での推論を行いたい場合には、以下の手順を行ってください。
- Step 1. OpenCVをインストールします
sudo apt-get install libopencv-dev
- Step 2. OpenCV Supportを使用してnvdsinfer_custom_impl_Yoloライブラリをコンパイルします。
cd ~/DeepStream-Yolo
CUDA_VER=11.4 OPENCV=1 make -C nvdsinfer_custom_impl_Yolo # for DeepStream 6.2/ 6.1.1 / 6.1
CUDA_VER=10.2 OPENCV=1 make -C nvdsinfer_custom_impl_Yolo # for DeepStream 6.0.1 / 6.0
-
Step 3. COCOデータセット用にval2017をダウンロードして展開します。その後、DeepStream-Yoloフォルダを移動します。
-
Step 4. キャリブレーション画像用のフォルダを新規作成します。
mkdir calibration
- Step 5. COCOデータセットからキャリブレーション用の画像を無作為に1000枚選択する、以下のコードを実行します。
for jpg in $(ls -1 val2017/*.jpg | sort -R | head -1000); do \
cp ${jpg} calibration/; \
done
注 : NVIDIAでは、充分な精度のために、少なくとも500枚の画像を使用してキャリブレーションを行うことを推奨しています。本Wikiでは更に高い精度のため、1000枚の画像を使用しています。より多くの画像を使用することで精度がより高まるためです。INT8_BATCH_SIZEの値が高いほど精度は高くなり、キャリブレーションの速度も速くなります。GPUメモリサイズに適した値を使用してください。head -1000からの値を設定できます。例えば、2000枚の画像を使用する場合にはhead -2000となります。このプロセスには時間がかかることが予想されます。
- Step 6. 選択されたすべての画像を含むcalibration.txtファイルを作成します。
realpath calibration/*jpg > calibration.txt
- Step 7. 環境設定を設定します。
export INT8_CALIB_IMG_PATH=calibration.txt
export INT8_CALIB_BATCH_SIZE=1
- Step 8. config_infer_primary_yoloV8.txtファイルをアップデートします。
...
model-engine-file=model_b1_gpu0_fp32.engine
#int8-calib-file=calib.table
...
network-mode=0
…
を以下のように変更します。
...
model-engine-file=model_b1_gpu0_int8.engine
int8-calib-file=calib.table
...
network-mode=1
…
-
Step 9. FPSの最大値で推論を行うためには、推論を実行する前にdeepstream_app_config.txtファイル内の[sink0]をtype=2に設定します。
-
Step 10. 推論を実行します。
deepstream-app -c deepstream_app_config.txt
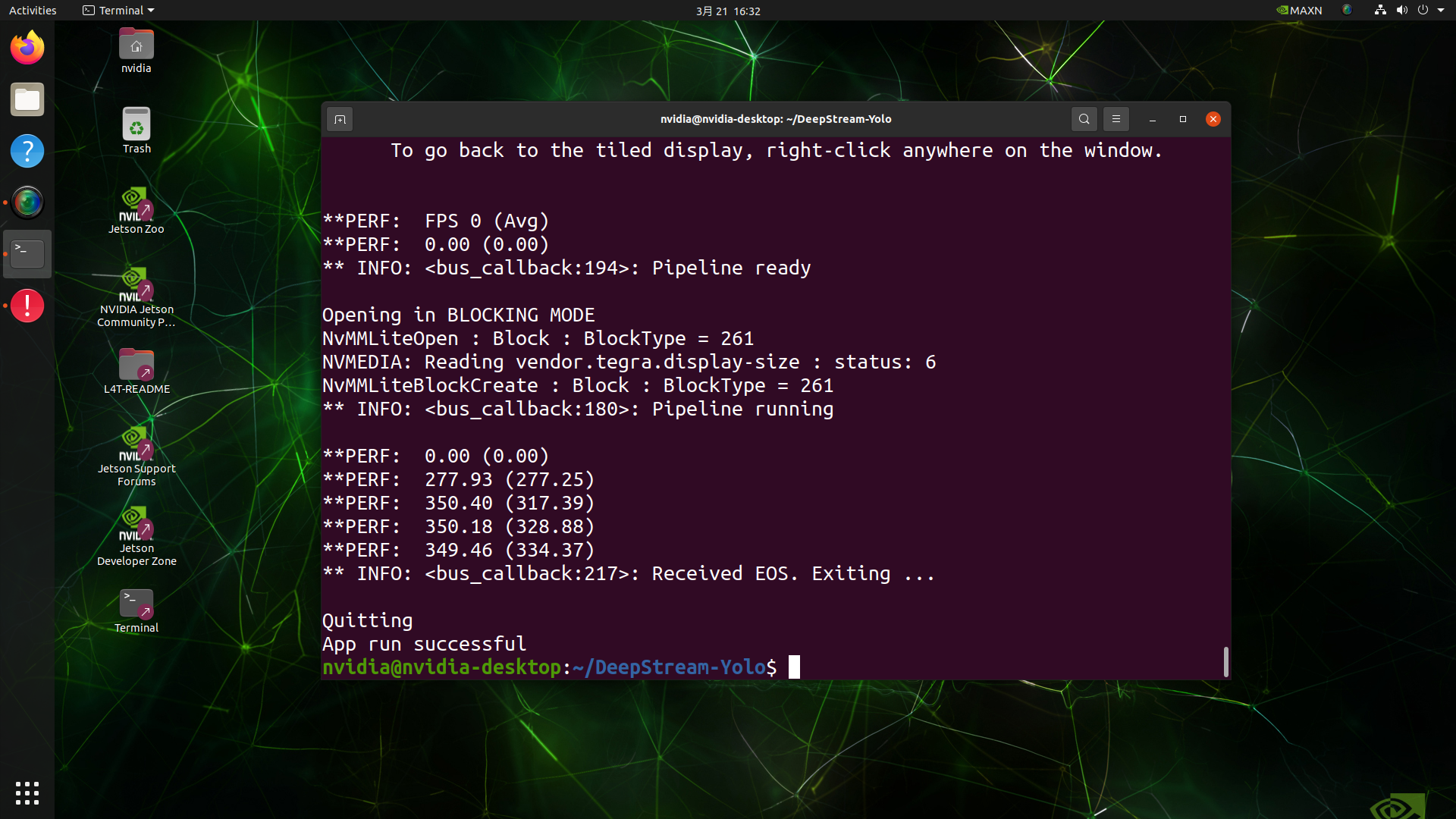
上はFPS 350で推論を行なっている場面です。
マルチストリーム設定
NVIDIA DeepStreamを使用して、ひとつの設定ファイルからマルチストリームのビデオ解析アプリケーションを簡単にセットアップすることができます。FPS性能の高いモデルがマルチストリームアプリケーションに与える良い影響については、ベンチマークと併せて、本Wiki内で解説します。
ここでは例として9ストリームでの設定について解説します。deepstream_app_config.txtファイルを以下に従って変更します。
- Step 1. [tiled-display]セクション以下の行と列をそれぞれ3に変更します。これにより9ストリーム、3 x 3のグリッドが得られます。
[tiled-display]
rows=3
columns=3
- Step 2. [source0]セクション以下のnum-sources=9を設定し、uriをさらに追加します。本wikiでは、ひとつのサンプルビデオファイルを8個複製し、合計9ストリームにした例で説明していますが、用途に合わせてビデオストリームの設定は変更しても構いません。
[source0]
enable=1
type=3
uri=file:///opt/nvidia/deepstream/deepstream/samples/streams/sample_1080p_h264.mp4
uri=file:///opt/nvidia/deepstream/deepstream/samples/streams/sample_1080p_h264.mp4
uri=file:///opt/nvidia/deepstream/deepstream/samples/streams/sample_1080p_h264.mp4
uri=file:///opt/nvidia/deepstream/deepstream/samples/streams/sample_1080p_h264.mp4
uri=file:///opt/nvidia/deepstream/deepstream/samples/streams/sample_1080p_h264.mp4
uri=file:///opt/nvidia/deepstream/deepstream/samples/streams/sample_1080p_h264.mp4
uri=file:///opt/nvidia/deepstream/deepstream/samples/streams/sample_1080p_h264.mp4
uri=file:///opt/nvidia/deepstream/deepstream/samples/streams/sample_1080p_h264.mp4
uri=file:///opt/nvidia/deepstream/deepstream/samples/streams/sample_1080p_h264.mp4
num-sources=9
deepstream-app-c deepstream_app_config.txtコマンドを使用してアプリケーションを実行すると、以下のような出力が得られます。
trtexec Tool
サンプルディレクトリ内には、コマンドラインラッピングツール trtexecが含まれています。trtexecを使用すれば、自分でアプリケーションの開発を行うことなくTensorRTと組み合わせて使用することができます。trtexecツールには主に以下の三つの機能があります。
- ランダムなデータ、もしくはユーザーが用意した入力データのネットワークベンチマーク
- モデルからシリアル化されたエンジンを生成する
- ビルダーからシリアル化されたタイミングキャッシュを生成する
本wikiでは、trtexecツールを使用して、異なるパラメータのモデルのベンチマークを行います。これには最初にonnxモデルの用意が必要です。Ultralytics YOLOv8を使用してonnxモデルを生成します。
- Step 1. 以下のコードを使用してONNXを作成します。
yolo mode=export model=yolov8s.pt format=onnx
- Step 2. trtexecを使用して、以下のようにエンジンを作成します。
cd /usr/src/tensorrt/bin
./trtexec --onnx=<path_to_onnx_file> --saveEngine=<path_to_save_engine_file>
本wikiのケースでは以下のようになります。
./trtexec --onnx=/home/nvidia/yolov8s.onnx –saveEngine=/home/nvidia/yolov8s.engine
生成された.engineファイルと一緒に、以下のようなベンチマーク結果が出力されます。デフォルトではONNXをTensorRTに適した形式に変換したFP32精度のファイルが生成されます。
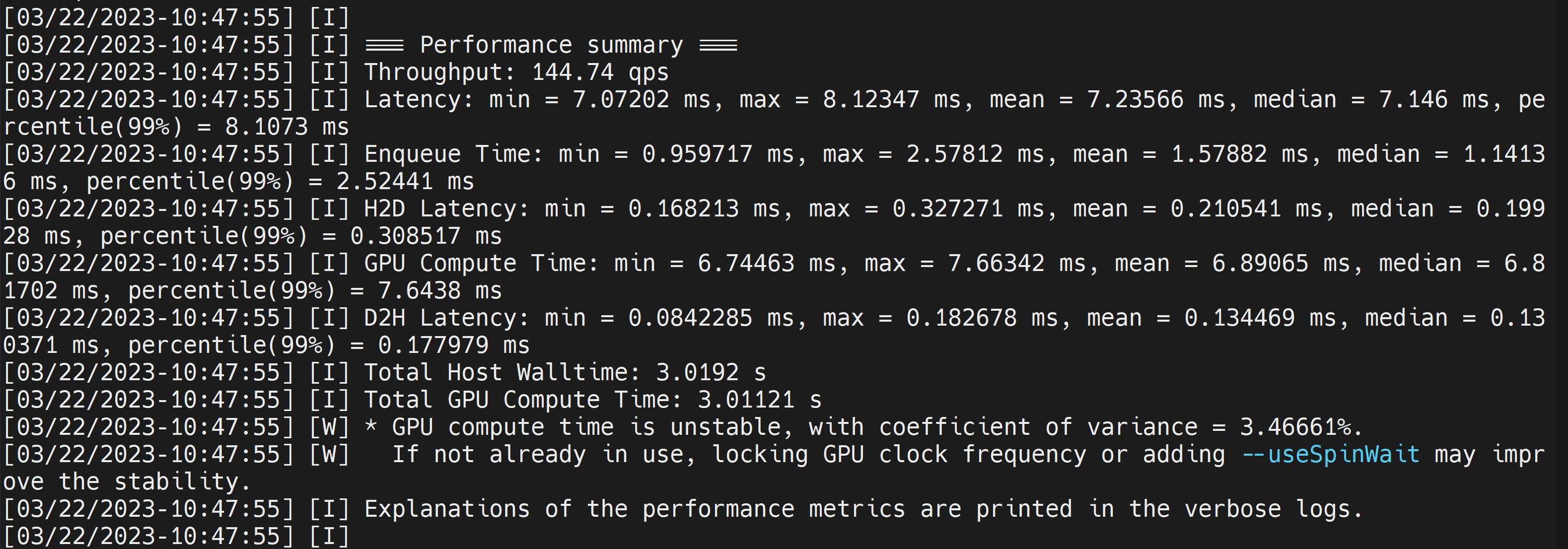
平均レイテンシは7.2ms(139FPS)で、上のDeepStreamでもで得られたベンチマークと同じ結果になっています。
さらに高いパフォーマンスのINT8精度が必要な場合には、上のコードを以下のように変更してください。
./trtexec --onnx=/home/nvidia/yolov8s.onnx --int8 --saveEngine=/home/nvidia/yolov8s.engine
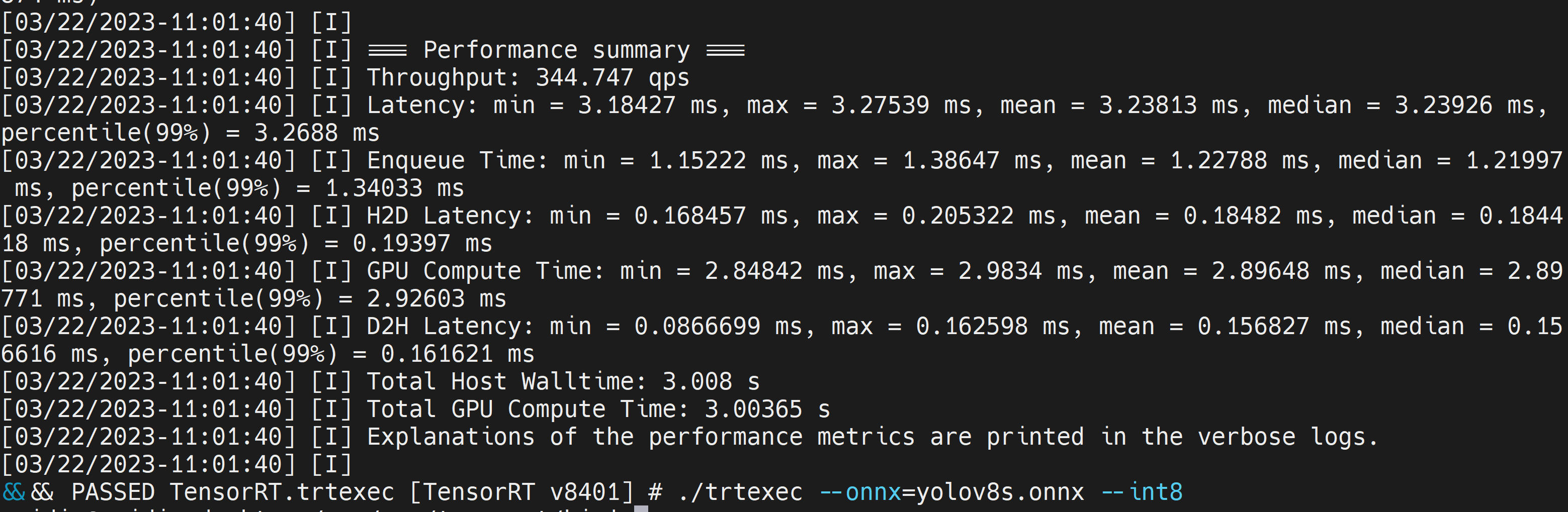
これにより平均レイテンシは3.2ms(313FPS)になっています。
YOLOv8のベンチマーク
以下はSeeedが実施したYOLOv8のベンチマーク結果です。複数の異なるYOLOv8モデルをreComputer J4012、AGX Orin 32GB H01 Kit、reComputer J2021で実行しています。
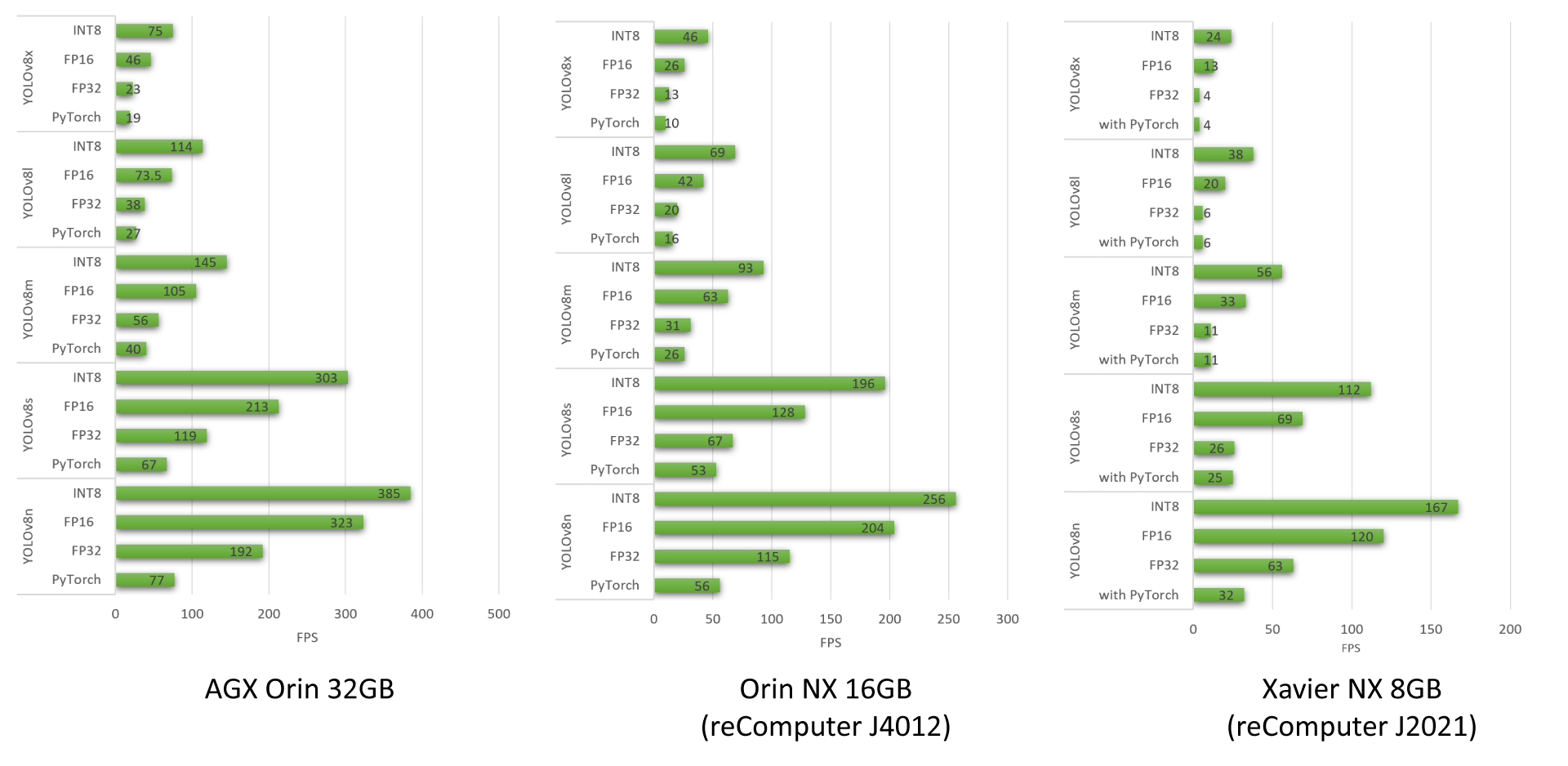
YOLOv8モデルを使用してSeeedが行ったベンチマークについての詳細はSeeedのブログをご覧ください。
マルチストリームモデルのベンチマーク
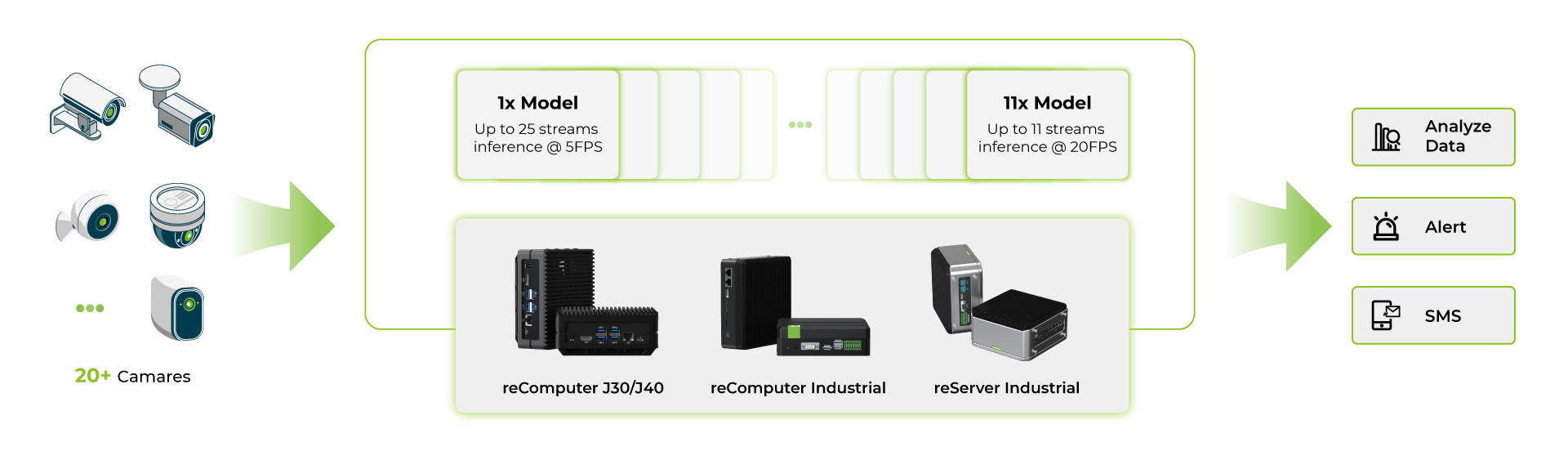
reComputer Jetson Orinシリーズ製品上で複数のDeepStreamアプリケーションを実行したのち、SeeedではYOLOv8sモデルを使用したベンチマークも行いました。
- まず、単一のAIモデルを使用し、マルチストリームを同一のAIモデル上で実行する
- 続いて、複数のAIモデルを使用し、マルチストリームを複数のAIモデル上で実行する。
全てのベンチマークは以下の環境で実施されています。
- YOLOv8s 640x640画像入力
- UI無効
- 最大パワー/最大性能モード オン
パラメータごとのベンチマーク結果についてはSeeedのwikiをご覧ください。
これらのベンチマークから、フラッグシップ機であるOrin NX 16GBでひとつのYOLOv8sモデルをINT8で実行した場合、約40台のカメラを5fps前後で使用可能で、複数のYOLOv8モデルの各ストリームをINT8で実行可能であることが分かります。また、約11台のカメラであれば15fps前後で使用可能です。複数のモデルを使用したケースでは、同時に使用できるカメラの台数は少なくなります。これはデバイス上のRAMの制限によるもので、各モデルがRAM上に一定の容量を占めているためです。
資料
テクニカルサポートと製品に関するフォーラム
ご購入いただいた製品をスムーズにお使いいただけるよう、Seeedでは様々なサポートを提供しています。ご希望に合わせてコンタクトの方法をお選びください。
出典 : Seeed Studio資料 Wiki - Deploy YOLOv8 with TensorRT and DeepStream SDK
https://wiki.seeedstudio.com/YOLOv8-DeepStream-TRT-Jetson/
*このガイドはSeeed Studioの許可を得て、スイッチサイエンスが翻訳しています。