YOLOv8をreComputerでトレーニングし、デプロイする
YOLOv8をreComputerでトレーニングし、デプロイする
はじめに
人々は、ますます複雑化しているダイナミックな課題に直面しています。その中で、人工知能の応用は問題解決への新たな道を提供し、グローバル社会の持続可能な発展と人々の生活の質の向上に大きく貢献しています。
通常、人工知能アルゴリズムを導入する前に、AIモデルの設計とトレーニングは高性能コンピューティング・サーバー上で行われます。モデルのトレーニングが完了すると、エッジ推論のためにエッジコンピューティングデバイスにエクスポートされます。
実際、これらのプロセスはすべて、エッジコンピューティングデバイス上で直接行うことができます。具体的には、データセットの準備、ニューラルネットワークのトレーニング、ニューラルネットワークの検証、モデルの展開などのタスクは、エッジデバイス上で実行が可能です。
これにより、データの安全性が確保されるだけでなく、デバイスの追加購入に伴うコストも節約できます。

本ドキュメントでは、reComputer J4012で交通シーンの物体検出モデルの学習とデプロイを行います。また、YOLOv8オブジェクト検出アルゴリズムを例として使用し、プロセス全体の詳細な概要を説明します。
以下に説明する操作はすべてJetsonエッジコンピューティングデバイス上で行われ、JetsonデバイスにJetPack 5.0以上のオペレーティングシステムがインストールされていることを確認してください。
データセット
機械学習のプロセスでは、与えられたデータの中からパターンを見つけ、そのパターンを捉えるために関数を使用します。したがって、データセットの質はモデルの性能に直接影響します。一般的に、学習データの質と量が高ければ高いほど、学習されたモデルの性能は向上します。よって、データセットの準備は非常に重要です。
学習データセットの収集には様々な方法があります。ここでは2つの方法を紹介します:1.注釈済みのオープンソース公開データセットをダウンロードする。2.トレーニングデータを収集し、注釈をつける。最後に、すべてのデータを統合し、後続のトレーニングフェーズに備える。
公開データセットのダウンロード
公開データセットは、機械学習や人工知能研究で広く利用されている標準化された共有データリソースです。これらのデータセットは、アルゴリズムの性能を評価するための標準的なベンチマークを研究者に提供し、この分野におけるイノベーションとコラボレーションを促進します。これらのデータセットは、AIコミュニティをよりオープンで革新的、そして持続可能な方向へと導きます。
RoboflowやKaggleなど、データセットを自由にダウンロードできるプラットフォームはたくさんありますが、ここではKaggleから交通シーンに関する注釈付きデータセット「Traffic Detection Project」をダウンロードします。
抽出後のファイル構造は以下の通りです:
archive
├── data.yaml
├── README.dataset.txt
├── README.roboflow.txt
├── test
│ ├── images
│ │ ├── aguanambi-1000_png_jpg.rf.7179a0df58ad6448028bc5bc21dca41e.jpg
│ │ ├── aguanambi-1095_png_jpg.rf.4d9f0370f1c09fb2a1d1666b155911e3.jpg
│ │ ├── ...
│ └── labels
│ ├── aguanambi-1000_png_jpg.rf.7179a0df58ad6448028bc5bc21dca41e.txt
│ ├── aguanambi-1095_png_jpg.rf.4d9f0370f1c09fb2a1d1666b155911e3.txt
│ ├── ...
├── train
│ ├── images
│ │ ├── aguanambi-1000_png_jpg.rf.0ab6f274892b9b370e6441886b2d7b9d.jpg
│ │ ├── aguanambi-1000_png_jpg.rf.dc59d3c5df5d991c1475e5957ea9948c.jpg
│ │ ├── ...
│ └── labels
│ ├── aguanambi-1000_png_jpg.rf.0ab6f274892b9b370e6441886b2d7b9d.txt
│ ├── aguanambi-1000_png_jpg.rf.dc59d3c5df5d991c1475e5957ea9948c.txt
│ ├── ...
└── valid
├── images
│ ├── aguanambi-1085_png_jpg.rf.0608a42a5c9090a4efaf9567f80fa992.jpg
│ ├── aguanambi-1105_png_jpg.rf.0aa6c5d1769ce60a33d7b51247f2a627.jpg
│ ├── ...
└── labels
├── aguanambi-1085_png_jpg.rf.0608a42a5c9090a4efaf9567f80fa992.txt
├── aguanambi-1105_png_jpg.rf.0aa6c5d1769ce60a33d7b51247f2a627.txt
├──...
各画像には、その画像の完全な注釈情報を含む対応するテキストファイルがあります。 data.jsonファイルには、トレーニングセット、テストセット、検証セットの場所が記録されているので、パスを変更する必要があります:
train: ./train/images
val: ./valid/images
test: ./test/images
nc: 5
names: ['bicycle', 'bus', 'car', 'motorbike', 'person']
データの収集と注釈
公開データセットがユーザーの要求に応えられない場合、特定のニーズに合わせたカスタムデータセットの収集と作成を検討する必要があります。
これは、関連するデータを収集し、アノテーションをし、整理することで実現できます。デモンストレーションのために、YouTubeから3つの画像をキャプチャして保存し、Label Studioを使って画像に注釈を付けてみました。
ステップ1.生データを収集します。

ステップ2.注釈ツールをインストールし、実行します。
sudo groupadd docker
sudo gpasswd -a ${USER} docker
sudo systemctl restart docker
sudo chmod a+rw /var/run/docker.sock
mkdir label_studio_data
sudo chmod -R 776 label_studio_data
docker run -it -p 8080:8080 -v $(pwd)/label_studio_data:/label-studio/data heartexlabs/label-studio:latest
ステップ3.新しいプロジェクトを作成し、プロンプトに従ってアノテーションを完成させます:Label Studioリファレンスドキュメント
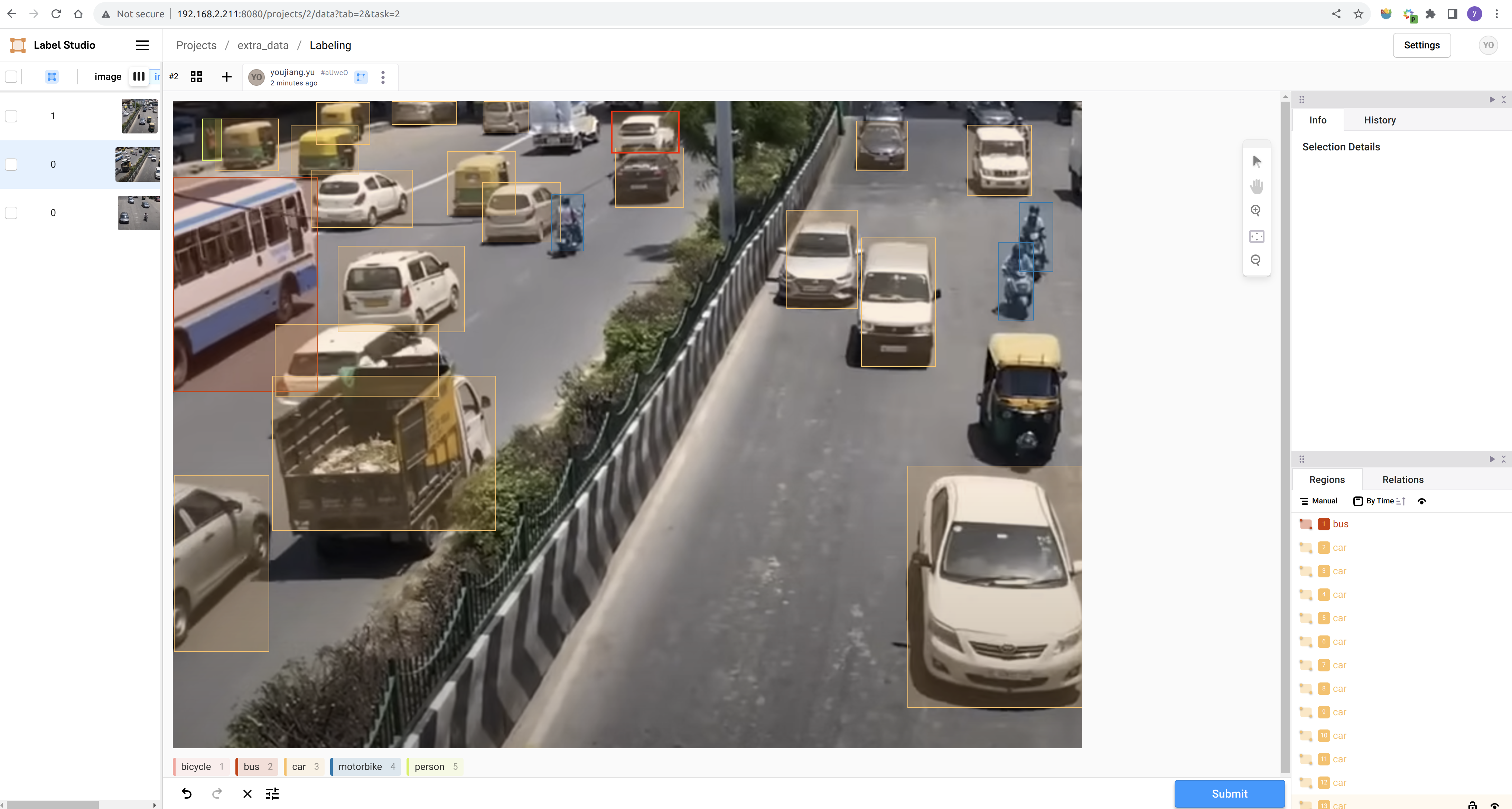
アノテーションが完了したら、データセットをYOLOフォーマットでエクスポートし、ダウンロードしたデータと一緒にアノテーションデータを整理することができます。 最も簡単な方法は、全ての画像を公開データセットのtrain/imagesフォルダにコピーし、生成されたアノテーションテキストファイルを公開データセットのtrain/labelsフォルダにコピーすることです。
この時点で、2つの異なる方法でトレーニングデータを取得し、それらを統合しました。より質の高いトレーニングデータを得たいのであれば、データクリーニングやクラスバランス調整など、考慮すべき追加ステップがたくさんあります。 我々のタスクは比較的単純なので、今はこれらのステップを省略し、上記で得られたデータを使ってトレーニングを進めることにします。
モデル
このセクションでは、reComputer上でYOLOv8のソースコードをダウンロードし、実行環境を設定します。
ステップ1.以下のコマンドでソースコードをダウンロードします。
git clone https://github.com/ultralytics/ultralytics.git
cd ultralytics
ステップ2.requirements.txtを開き、関連する内容を修正します。
# ファイルを開くには`vi`コマンドを使います。
vi requirements.txt
# `a`を押して編集モードに入り、以下の内容を変更します。
torch>=1.7.0 --> # torch>=1.7.0
torchvision>=0.8.1 --> # torchvision>=0.8.1
# `ESC`を押して編集モードを終了し、最後に`:wq`を入力してファイルを保存して終了します。
ステップ3.以下のコマンドを実行して、YOLOに必要な依存関係をダウンロードし、YOLOv8をインストールします:
pip3 install -e .
cd ..
ステップ4.JetsonバージョンのPyTorchをインストールします。
sudo apt-get install -y libopenblas-base libopenmpi-dev
wget https://developer.download.nvidia.cn/compute/redist/jp/v512/pytorch/torch-2.1.0a0+41361538.nv23.06-cp38-cp38-linux_aarch64.whl -O torch-2.1.0a0+41361538.nv23.06-cp38-cp38-linux_aarch64.whl
pip3 install torch-2.1.0a0+41361538.nv23.06-cp38-cp38-linux_aarch64.whl
ステップ5.対応するTorchvisionをインストールします。
sudo apt install -y libjpeg-dev zlib1g-dev
git clone --branch v0.16.0 https://github.com/pytorch/vision torchvision
cd torchvision
python3 setup.py install --user
cd ..
ステップ6.以下のコマンドを使用して、YOLOが正常にインストールされたことを確認します。
yolo detect predict model=yolov8s.pt source='https://ultralytics.com/images/bus.jpg'
訓練
モデルのトレーニングとは、モデルの重みを更新するプロセスです。 モデルを訓練することで、機械学習アルゴリズムはデータから学習し、パターンや関係を認識することができるようになり、新しいデータに対する予測や意思決定が可能になります。
ステップ1.トレーニング用のPythonスクリプトを作成する:
vi train.py
「a」を押して編集モードに入り、以下の内容を変更します:
from ultralytics import YOLO
# Load a model
model = YOLO('yolov8s.pt')
# Train the model
results = model.train(
data='/home/nvidia/Everything_Happens_Locally/Dataset/data.yaml',
batch=8, epochs=100, imgsz=640, save_period=5
)
ESCキーを押して編集モードを終了し、最後に:wqを入力してファイルを保存して終了します。 YOLO.train()メソッドには多くの設定パラメータがあります。詳細はドキュメントを参照してください。 さらに、より合理的なCLIアプローチを使用して、特定の要件に基づいてトレーニングを開始することもできます。
ステップ2.以下のコマンドでトレーニングを開始します。
python3 train.py
その後、長い待ち時間が発生します。待ち時間の間にリモート接続ウィンドウを閉じてしまう可能性を考慮し、このチュートリアルではTmuxターミナル・マルチプレクサを使用しています。 従って、処理中に私が見るインターフェースは次のようになります:
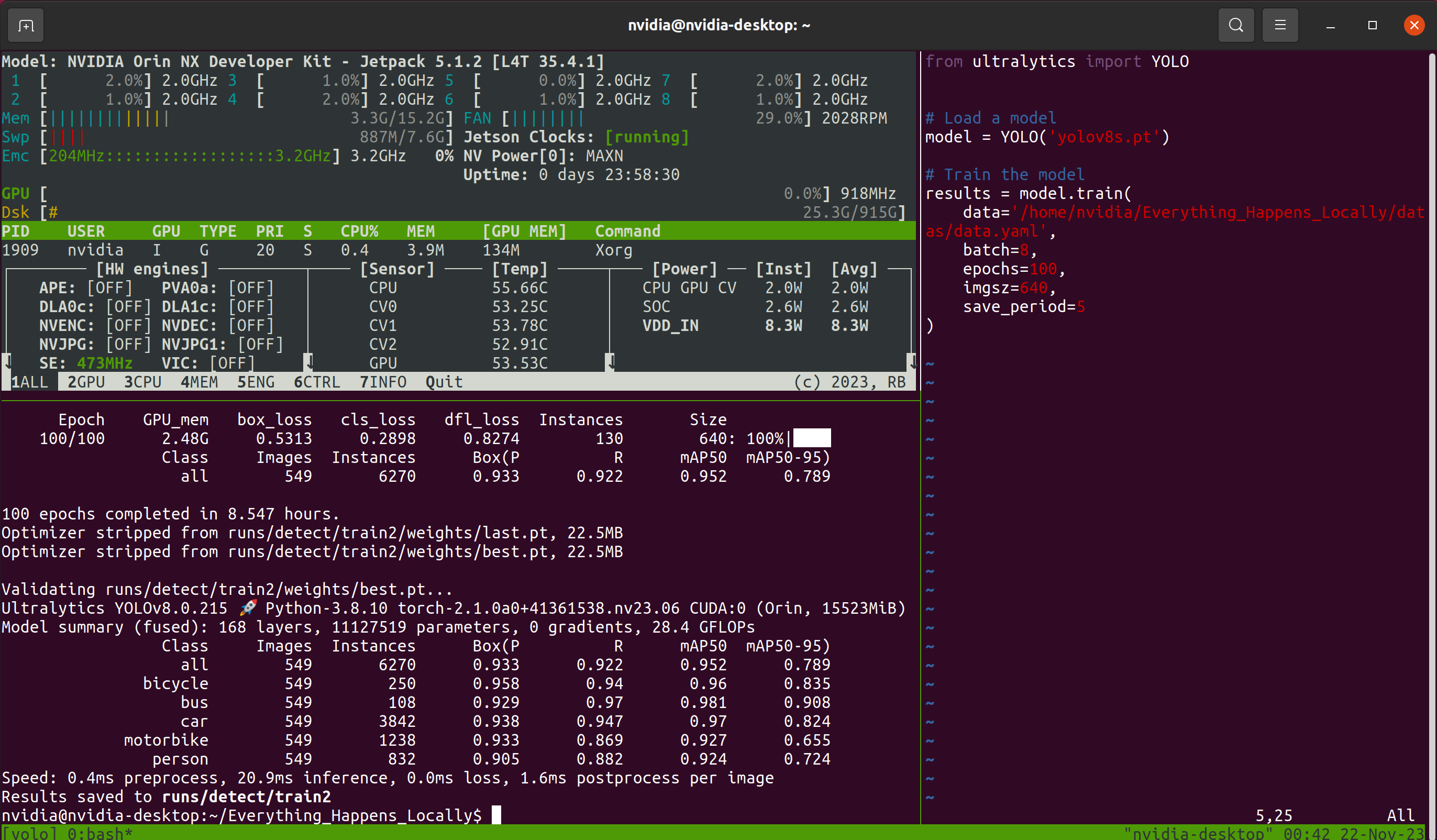
モデルが正常にトレーニングされている限り、Tmuxはオプションです。 トレーニングプログラムが終了すると、トレーニング中に保存されたモデルのウェイトファイルが指定のフォルダに保存されます:

検証
検証プロセスでは、データの一部を使用してモデルの信頼性を検証します。このプロセスは、モデルが実世界のアプリケーションでタスクを正確かつロバストに実行できることを保証するのに役立ちます。トレーニングプロセス中に出力される情報をよく調べると、トレーニング中に多くの検証が散りばめられていることに気づくでしょう。このセクションでは、各評価指標の意味を分析するのではなく、予測結果を検証することで、モデルの使いやすさを分析します。
ステップ1.学習済みモデルを使用して、特定の画像を推測します。
yolo detect predict \
model='./runs/detect/train2/weights/best.pt' \
source='./datas/test/images/ant_sales-2615_png_jpg.rf.0ceaf2af2a89d4080000f35af44d1b03.jpg' \
save=True show=False
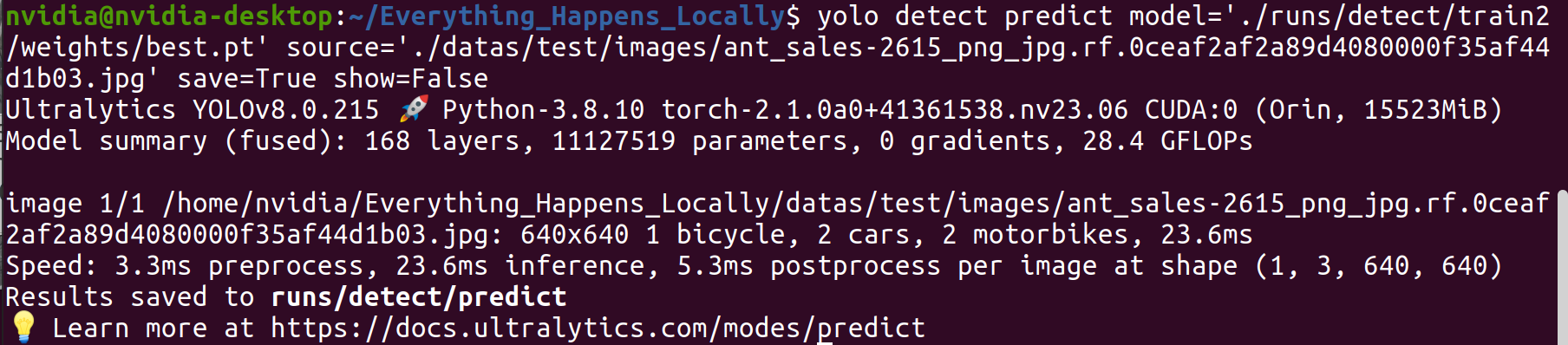
ステップ2.推論結果を調べます。
検出結果から、学習済みモデルは期待通りの検出性能を達成していることが確認できます。

Deployment/配備
デプロイメントとは、学習済みの機械学習モデルやディープラーニングモデルを実世界のシナリオに適用するプロセスです。上で紹介した内容は、モデルの実現可能性を検証したものだが、モデルの推論効率については考慮していません。デプロイ段階では、検出精度と効率のバランスを見つける必要があります。TensorRT推論エンジンを使用することで、モデルの推論速度を向上させることができます。
ステップ1.軽量モデルとオリジナルモデルの対比を視覚的に示すために、viツールを使って新しいinference.pyファイルを作成し、ビデオファイルの推論を実装します。8行目と9行目を修正することで、推論モデルと入力ビデオを置き換えることができます。このドキュメントの入力は、私が携帯電話で撮影したビデオです。
from ultralytics import YOLO
import os
import cv2
import time
import datetime
model = YOLO("/home/nvidia/Everything_Happens_Locally/runs/detect/train2/weights/best.pt")
cap = cv2.VideoCapture('./sample_video.mp4')
save_dir = os.path.join('runs/inference_test', datetime.datetime.now().strftime('%Y-%m-%d-%H-%M-%S'))
if not os.path.exists(save_dir):
os.makedirs(save_dir)
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
fps = cap.get(cv2.CAP_PROP_FPS)
size = (int(cap.get(cv2.CAP_PROP_FRAME_WIDTH)), int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT)))
output = cv2.VideoWriter(os.path.join(save_dir, 'result.mp4'), fourcc, fps, size)
while cap.isOpened():
success, frame = cap.read()
if success:
start_time = time.time()
results = model(frame)
annotated_frame = results[0].plot()
total_time = time.time() - start_time
fps = 1/total_time
cv2.rectangle(annotated_frame, (20, 20), (200, 60), (55, 104, 0), -1)
cv2.putText(annotated_frame, f'FPS: {round(fps, 2)}', (30, 50), 0, 0.9, (255, 255, 255), thickness=2, lineType=cv2.LINE_AA)
print(f'FPS: {fps}')
cv2.imshow("YOLOv8 Inference", annotated_frame)
output.write(annotated_frame)
if cv2.waitKey(1) & 0xFF == ord("q"):
break
else:
break
cv2.destroyAllWindows()
cap.release()
output.release()
ステップ2. 以下のコマンドを実行し、モデル量子化前の推論速度を記録します。
python3 inference.py

その結果、量子化前のモデルの推論速度は21.9FPSでした。
ステップ3.量子化モデルを生成します。
pip3 install onnx
yolo export model=/home/nvidia/Everything_Happens_Locally/runs/detect/train2/weights/best.pt format=engine half=True device=0
プログラムが完了すると(約10-20分)、入力モデルと同じディレクトリに.engineファイルが生成されます。このファイルが量子化されたモデルです。

ステップ4.量子化モデルを用いて推論速度をテストします。
ここで、ステップ1で作成したスクリプトの8行目の内容を修正する必要があります。
model = YOLO(<path to .pt>) --> model = YOLO(<path to .engine>)
その後、推論コマンドを再実行します:
python3 inference.py

推論効率の観点から見ると、量子化モデルは推論スピードの大幅な向上を示しています。
概要
この記事は、データ収集、モデル・トレーニングからデプロイまで、様々な側面をカバーする包括的なガイドを読者に提供します。重要なのは、すべてのプロセスがreComputerで行われるため、ユーザーがGPUを追加する必要がないことです。
テクニカルサポートと製品に関するフォーラム
ご購入いただいた製品をスムーズにお使いいただけるよう、Seeedでは様々なサポートを提供しています。ご希望に合わせてコンタクトの方法をお選びください。
出典 : Seeed Studio資料 Wiki - How to Train and Deploy YOLOv8 on reComputer
https://wiki.seeedstudio.com/How_to_Train_and_Deploy_YOLOv8_on_reComputer/
*このガイドはSeeed Studioの許可を得て、スイッチサイエンスが翻訳しています。