TensorRTを使用してNVIDIA Jetson上でYOLOv8を使用する
TensorRTを使用してNVIDIA Jetson上でYOLOv8を使用する
本Wikiガイドでは、NVIDIA Jetsonプラットフォーム上でのYOLOv8モデルの使用方法と、TensorRTでの推論の方法について説明します。TensorRTを使用することでJetsonプラットフォームでの推論のパフォーマンスを最大限に利用することができます。
以下のような異なるシチュエーションでのマシンビジョンタスクについての説明が含まれます。
- オブジェクト検知
- 画像セグメンテーション
- 画像分類
- 姿勢推定
- オブジェクトトラッキング

本ガイドの学習に必要なもの
- UbuntuをインストールしたPC(Ubuntuネイティブ環境、またはVMware Workstation Playerを使用したVM環境)
- JetPack 5.1.1以降で動作するreComputer Jetsonまたはその他のNVIDIA Jetson製品
注 : 本WikiはNVIDIA Jetson Orin NX 16 GBモジュールでreComputer J4012とreComputer Industrial J4012を使用してテスト及び検証されています。
JetsonへのJetPackの書き込み
CUDA、TensorRT、cuDNNなどのSDKコンポーネントを含むJetPackシステムがJetsonデバイスに書き込まれていることを確認してください。NVIDIA SDK Managerもしくはコマンドラインで書き込みが行えます。
SeeedのJetsonデバイスへの書き込みについては以下のリンクをご覧ください。
- reComputer J1010/J101
- reComputer J2021/J202
- reComputer J1020/A206
- reComputer J4012/J401
- A203 Carrier Board
- A205 Carrier Board
- Jetson Xavier AGX H01 Kit
- Jetson AGX Orin 32GB H01 Kit
注 : 本WikiはJetPack v5.1.1で検証しています。デバイスへはv5.1.1を書き込んでください。
1行のコードでJetsonへYOLOv8をインストールする
JetsonにJetPackをインストールしたあとは、以下のコードを実行するだけでYOLOv8のインストールが可能です。最初に必要不可欠なパッケージや環境依存ファイルをインストールし、続いて、環境設定や、YOLOv8でオブジェクト検知や画像セグメンテーション、姿勢推定、画像分類を実行するのに必要な事前学習モデルのダウンロードを行います。
wget files.seeedstudio.com/YOLOv8-Jetson.py && python YOLOv8-Jetson.py
注 :
上記のスクリプトのソースコードはこちらをご覧ください。
事前学習モデルを使用する
YOLOv8を使い始めるのに最も簡単な方法は、公式に提供されている事前学習モデルを利用することです。ですが、これらはPyTorchモデルのため、Jetsonと組み合わせた場合にはCPUを利用することしかできません。Jetson上でGPUを使用し、モデルのパフォーマンスを発揮させたい場合には、以下を参照してPyTorchモデルをTensorRTに変換してください。
オブジェクト検知
YOLOv8からは5種類のPyTorch事前学習モデルが提供されています。オブジェクト検知に重点を置いたモデルで、640 x 640サイズの画像をCOCOデータセットに読み込ませてあらかじめ事前学習を行なったものです。
| モデル | 画像サイズ (ピクセル) | mAPval 50-95 | CPU ONNX速度 (ms) | A100 TensorRT速度 (ms) | params (M) | FLOPs (B) |
|---|---|---|---|---|---|---|
| YOLOv8n | 640 | 37.3 | 80.4 | 0.99 | 3.2 | 8.7 |
| YOLOv8s | 640 | 44.9 | 128.4 | 1.20 | 11.2 | 28.6 |
| YOLOv8m | 640 | 50.2 | 234.7 | 1.83 | 25.9 | 78.9 |
| YOLOv8l | 640 | 52.9 | 375.2 | 2.39 | 43.7 | 165.2 |
| YOLOv8x | 640 | 53.9 | 479.1 | 3.53 | 68.2 | 257.8 |
資料 : https://docs.ultralytics.com/tasks/detect
上の表から希望のモデルをダウンロードし、以下のコマンドを実行することで画像推論が行えます。
wget yolo detect predict model=yolov8n.pt source='https://ultralytics.com/images/bus.jpg' show=True
コード内の記述をyolov8s.pt、yolov8m.pt、yolov8l.pt、yolov8x.ptのいずれかに変更することで、対応した事前学習モデルがダウンロードされます。
ウェブカメラを接続して以下のコマンドを実行することもできます。
yolo detect predict model=yolov8n.pt source='0' show=True
注 : 上記のコマンドを実行した際にエラーが発生する場合には、コマンドの末尾にdevice=0を加えてみてください。

注 :
上の画像はreComputer J4012/ reComputer Industrial J4012を使用し、640 x 640サイズの画像で学習を行なったYOLOv8モデル(TensorRT FP16精度)を使用したものです。
画像分類
YOLOv8からは5種類のPyTorch事前学習モデルが提供されています。224 x 224サイズの画像を使用し、ImageNetで事前学習が行われています。
| モデル | 画像サイズ (ピクセル) | acc top1 | acc top5 | CPU ONNX速度 (ms) | A100 TensorRT速度 (ms) | params (M) | FLOPs (B)@640 |
|---|---|---|---|---|---|---|---|
| YOLOv8n-cls | 224 | 66.6 | 87.0 | 12.9 | 0.31 | 2.7 | 4.3 |
| YOLOv8s-cls | 224 | 72.3 | 91.1 | 23.4 | 0.35 | 6.4 | 13.5 |
| YOLOv8m-cls | 224 | 76.4 | 93.2 | 85.4 | 0.62 | 17.0 | 42.7 |
| YOLOv8l-cls | 224 | 78.0 | 94.1 | 163.0 | 0.87 | 37.5 | 99.7 |
| YOLOv8x-cls | 224 | 78.4 | 94.3 | 232.0 | 1.01 | 57.4 | 154.8 |
資料 : https://docs.ultralytics.com/tasks/classify
希望のモデルをダウンロードし、以下のコマンドを実行することで画像推論が行えます。
yolo classify predict model=yolov8n-cls.pt source='https://ultralytics.com/images/bus.jpg' show=True
コード内の記述をyolov8s-cls.pt、yolov8m-cls.pt、yolov8l-cls.pt、yolov8x-cls.ptのいずれかに変更することで、対応した事前学習モデルがダウンロードされます。
ウェブカメラを接続して以下のコマンドを実行することもできます。
yolo classify predict model=yolov8n-cls.pt source='0' show=True
注 : 上記のコマンドを実行した際にエラーが発生する場合には、コマンドの末尾にdevice=0を加えてみてください。
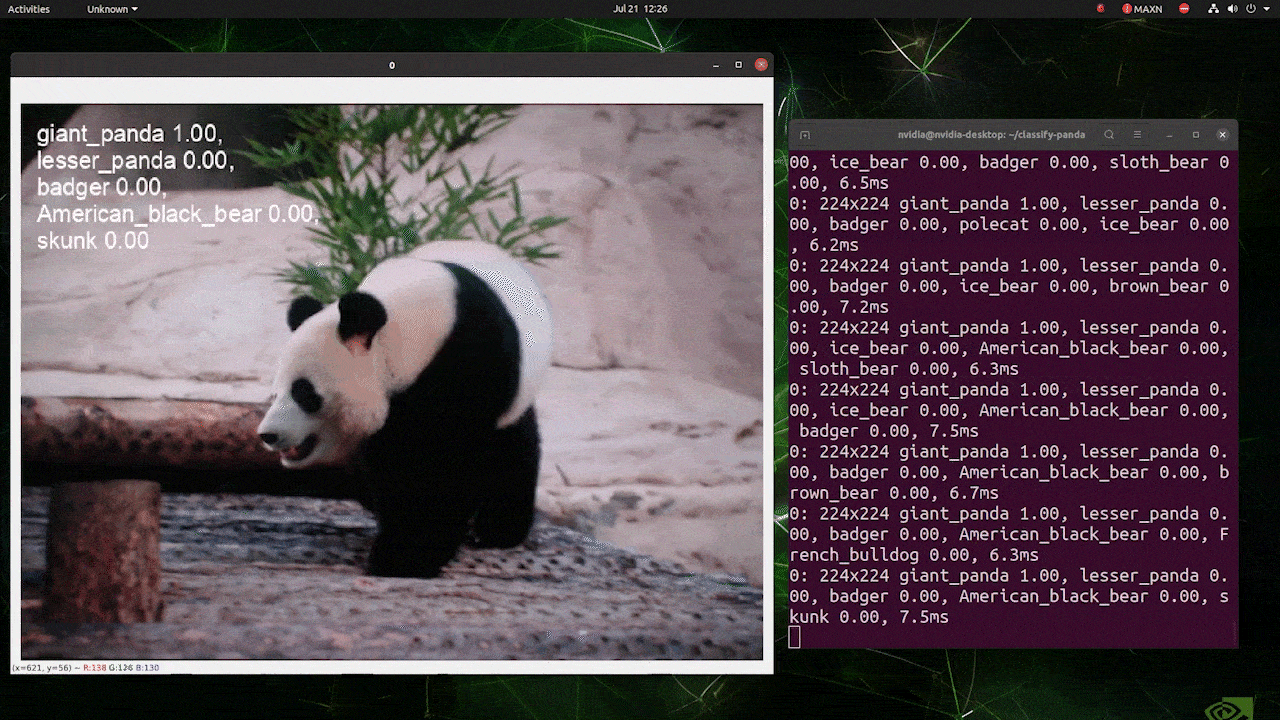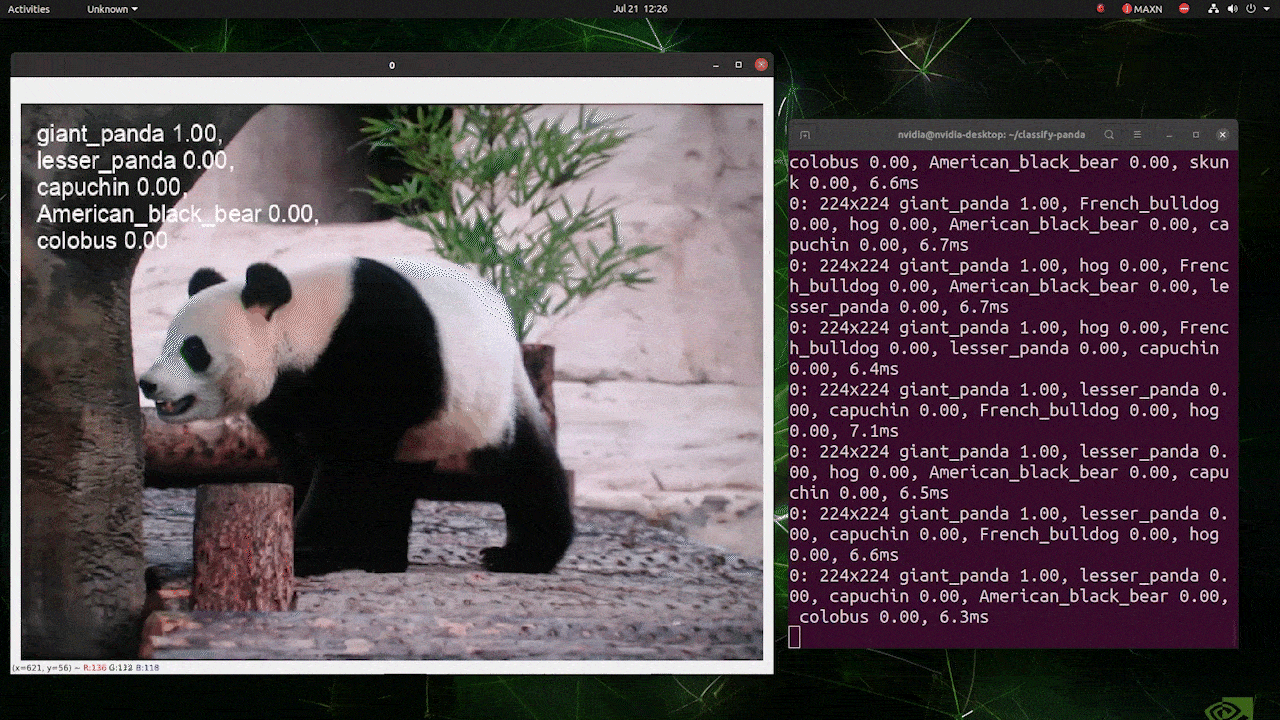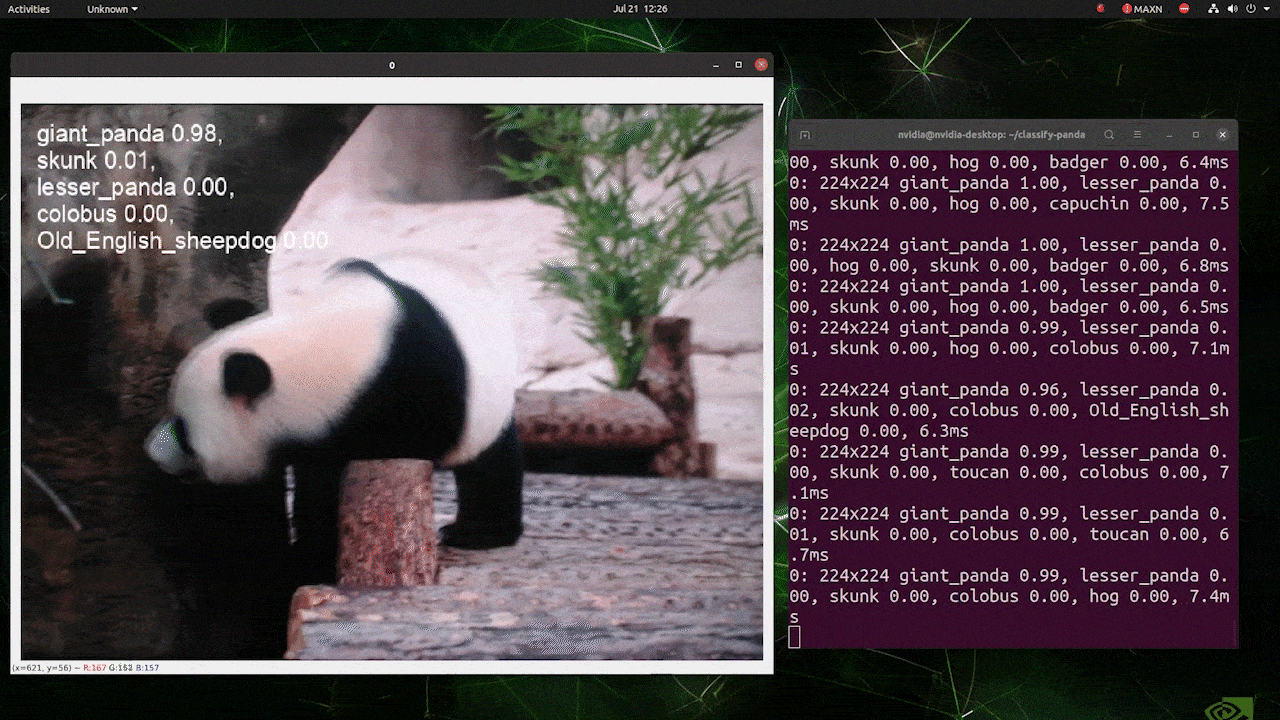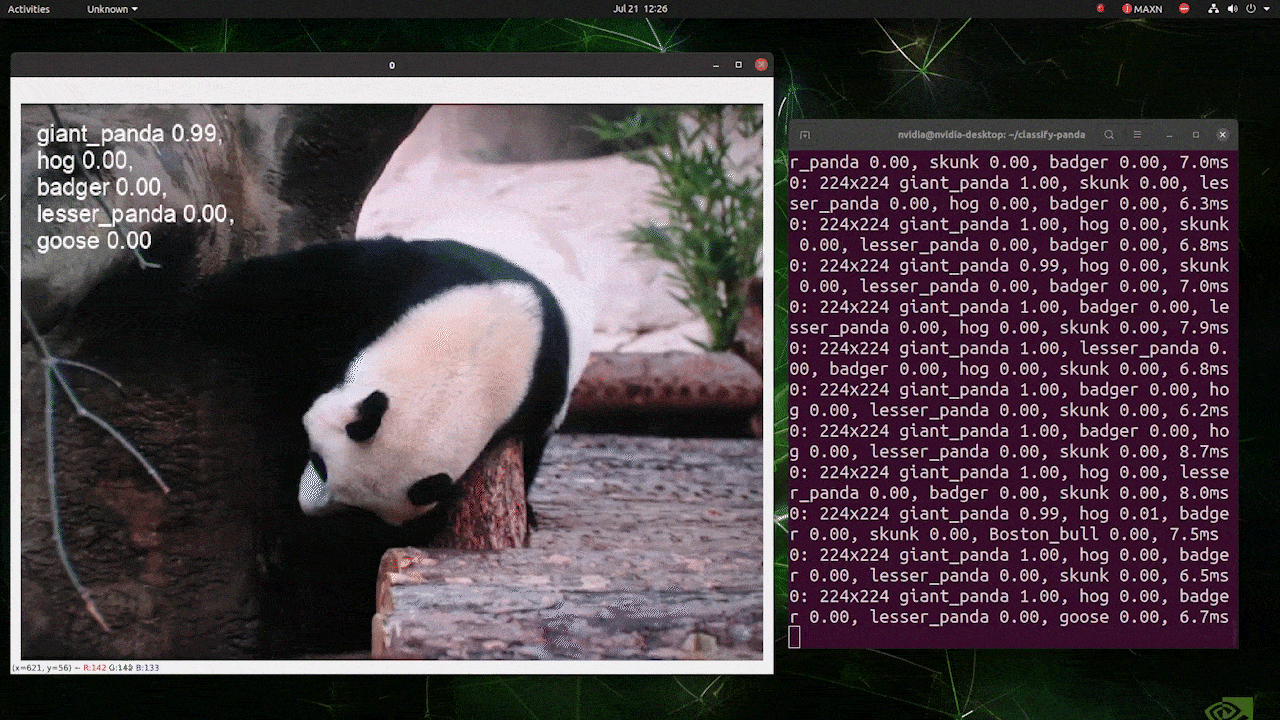
注 :
上の画像はreComputer J4012/ reComputer Industrial J4012を使用し、224 x 224サイズの画像で学習を行なったYOLOv8-clsモデル(TensorRT FP16精度)を使用したものです。TensorRTモデルを使用する場合、推論エンジンはデフォルトで640サイズの画像を扱うように設定されているため、必ずTensorRT エクスポートを使用して推論コマンドに引数 imgsz=224を渡してください。
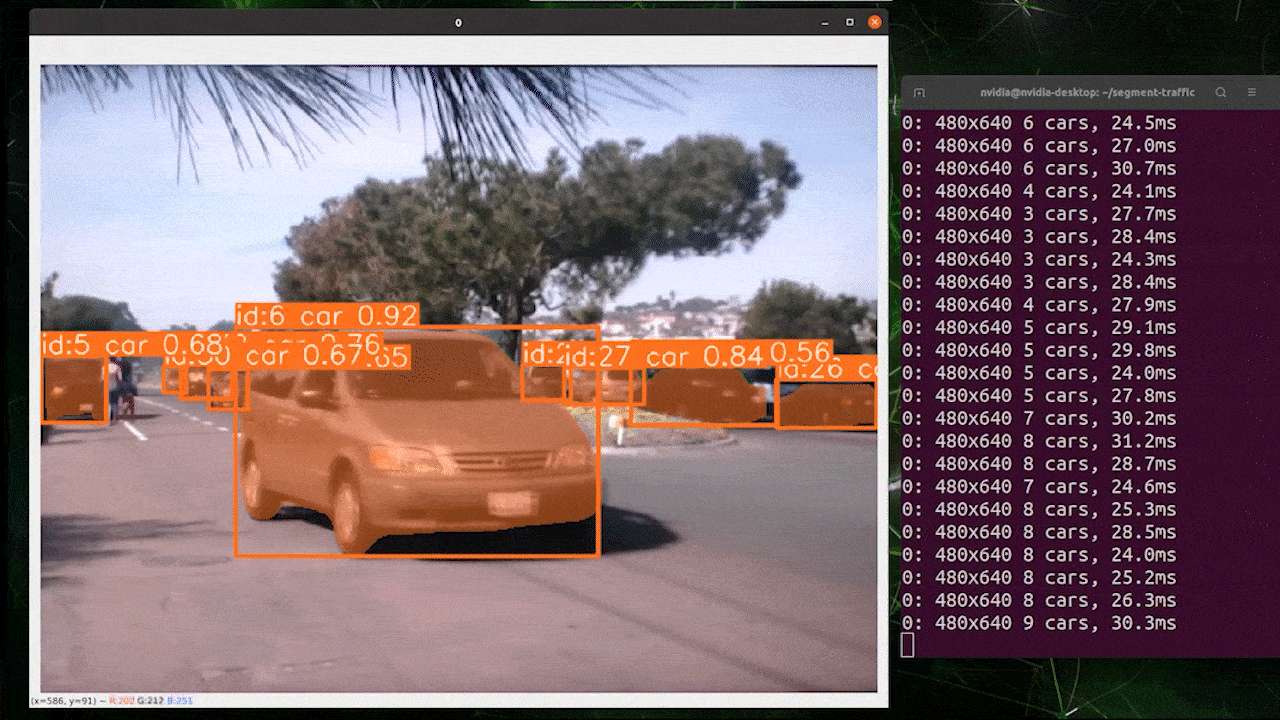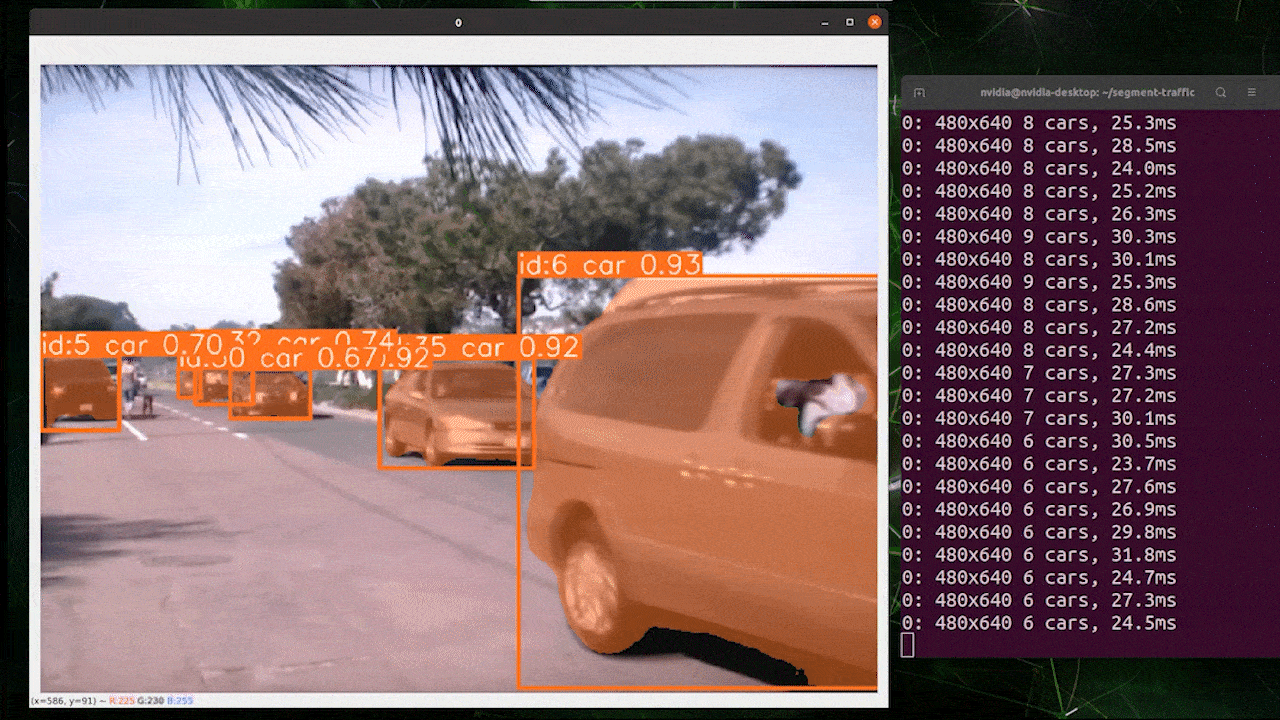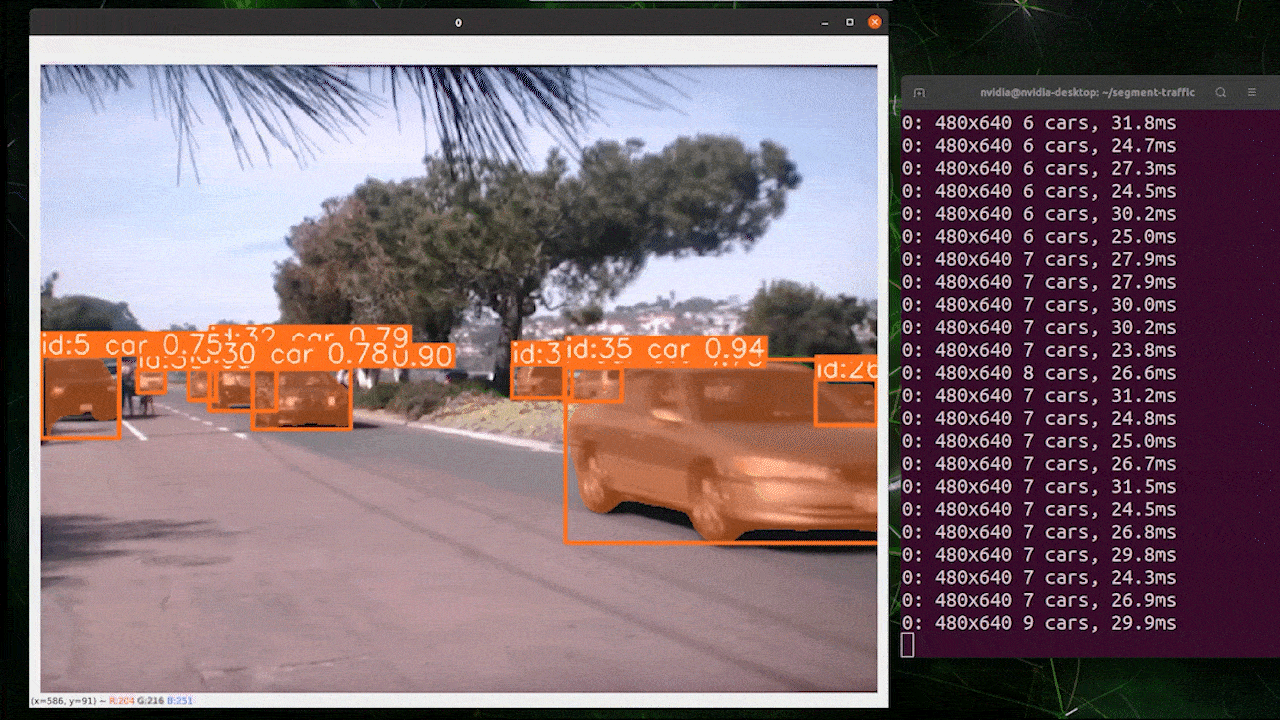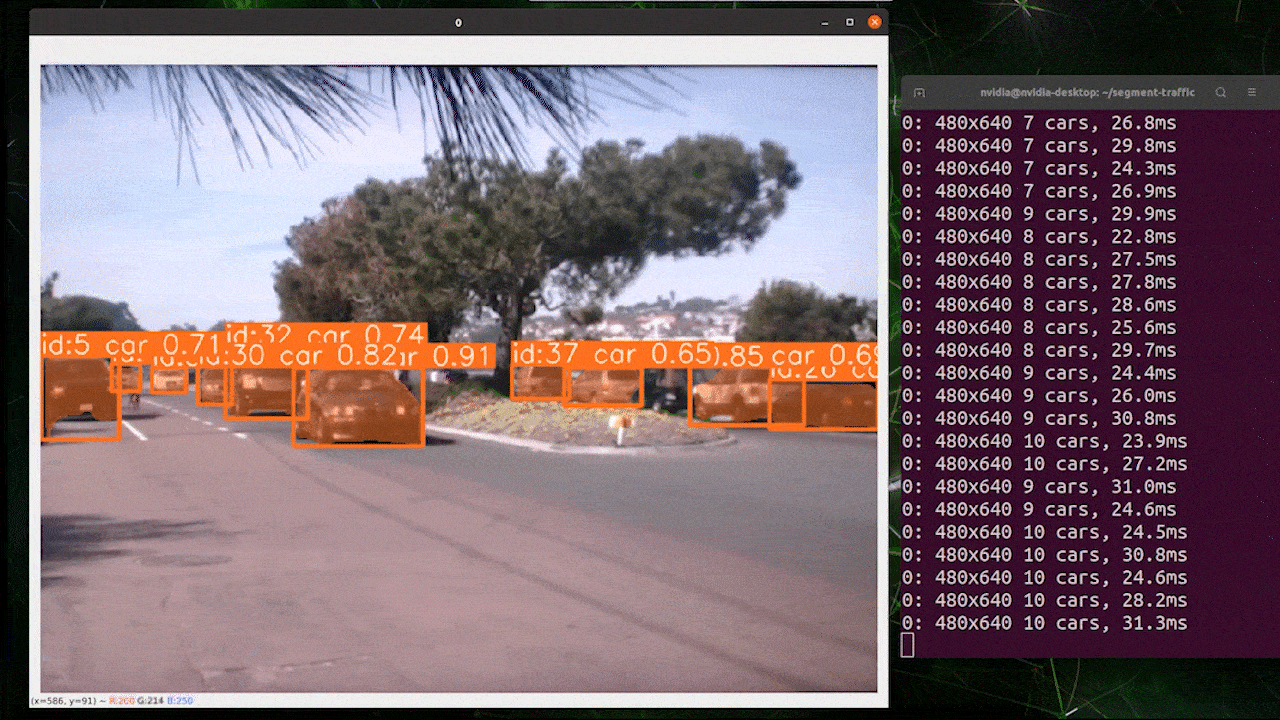
画像セグメンテーション
YOLOv8からは5種類のPyTorch事前学習モデルが提供されています。画像セグメンテーションに重点を置いたモデルで、640 x 640サイズの画像をCOCOデータセットに読み込ませて事前学習が行われています。
| モデル | 画像サイズ (ピクセル) | mAPbox 50-95 | mAPmask 50-95 | CPU ONNX速度 (ms) | A100 TensorRT速度 (ms) | params (M) | FLOPs (B) |
|---|---|---|---|---|---|---|---|
| YOLOv8n-seg | 640 | 36.7 | 30.5 | 96.1 | 1.21 | 3.4 | 12.6 |
| YOLOv8s-seg | 640 | 44.6 | 36.8 | 155.7 | 1.47 | 11.8 | 42.6 |
| YOLOv8m-seg | 640 | 49.9 | 40.8 | 317.0 | 2.18 | 27.3 | 110.2 |
| YOLOv8l-seg | 640 | 52.3 | 42.6 | 572.4 | 2.79 | 46.0 | 220.5 |
| YOLOv8x-seg | 640 | 53.4 | 43.4 | 712.1 | 4.02 | 71.8 | 344.1 |
資料 : https://docs.ultralytics.com/tasks/segment
希望のモデルをダウンロードし、以下のコマンドを実行することで画像推論が行えます。
yolo segment predict model=yolov8n-seg.pt source='https://ultralytics.com/images/bus.jpg' show=True
コード内の記述をyolov8s-seg.pt、yolov8m-seg.pt、yolov8l-seg.pt、yolov8x-seg.pのいずれかに変更することで、対応した事前学習モデルがダウンロードされます。
ウェブカメラを接続して以下のコマンドを実行することもできます。
yolo segment predict model=yolov8n-seg.pt source='0' show=True
注 : 上記のコマンドを実行した際にエラーが発生する場合には、コマンドの末尾にdevice=0を加えてみてください。

注 :
上の画像はreComputer J4012/ reComputer Industrial J4012を使用し、640 x 640サイズの画像で学習を行なったYOLOv8-clsモデル(TensorRT FP16精度)を使用したものです。
姿勢推定
YOLOv8からは6種類のPyTorch事前学習モデルが提供されています。姿勢推定に重点を置いたモデルで、640 x 640サイズの画像をCOCOキーポイントデータセットに読み込ませて事前学習が行われています。
| モデル | 画像サイズ (ピクセル) | mAPpose 50-95 | mAPpose 50 | CPU ONNX速度 (ms) | A100 TensorRT速度 (ms) | params (M) | FLOPs (B) |
|---|---|---|---|---|---|---|---|
| YOLOv8n-pose | 640 | 50.4 | 80.1 | 131.8 | 1.18 | 3.3 | 9.2 |
| YOLOv8s-pose | 640 | 60.0 | 86.2 | 233.2 | 1.42 | 11.6 | 30.2 |
| YOLOv8m-pose | 640 | 65.0 | 88.8 | 456.3 | 2.00 | 26.4 | 81.0 |
| YOLOv8l-pose | 640 | 67.6 | 90.0 | 784.5 | 2.59 | 44.4 | 168.6 |
| YOLOv8x-pose | 640 | 69.2 | 90.2 | 1607.1 | 3.73 | 69.4 | 263.2 |
| YOLOv8x-pose-p6 | 1280 | 71.6 | 91.2 | 4088.7 | 10.04 | 99.1 | 1066.4 |
資料 : https://docs.ultralytics.com/tasks/pose
希望のモデルをダウンロードし、以下のコマンドを実行することで画像推論が行えます。
yolo pose predict model=yolov8n-pose.pt source='https://ultralytics.com/images/bus.jpg'
コード内の記述をyolov8s-pose.pt、yolov8m-pose.pt、yolov8l-pose.pt、yolov8x-pose.pt、yolov8x-pose-p6のいずれかに変更することで、対応した事前学習モデルがダウンロードされます。
ウェブカメラを接続して以下のコマンドを実行することもできます。
yolo pose predict model=yolov8n-pose.pt source='0'
注 : 上記のコマンドを実行した際にエラーが発生する場合には、コマンドの末尾にdevice=0を加えてみてください。

オブジェクトトラッキング
対象のオブジェクトの位置とクラスを認識し、ビデオストリーミング内の検知結果にユニークIDを割り振ることで、オブジェクトトラッキングが行われます。
オブジェクトトラッキングの出力結果は、基本的にはオブジェクト検知にオブジェクトIDが付加されたものです。
資料 : https://docs.ultralytics.com/modes/track
オブジェクト検知/画像セグメンテーションの結果をもとに希望のモデルをダウンロードし、以下のコマンドを実行することで、ビデオ上で推論が行えます。
yolo track model=yolov8n.pt source="https://youtu.be/Zgi9g1ksQHc"
コード内の記述をyolov8n.pt、yolov8s.pt、yolov8m.pt、yolov8l.pt、yolov8x.pt、yolov8n-seg.pt、yolov8s-seg.pt、yolov8m-seg.pt、yolov8l-seg.pt、yolov8x-seg.ptのいずれかに変更することで、対応した事前学習モデルがダウンロードされます。
ウェブカメラを接続して以下のコマンドを実行することもできます。
yolo track model=yolov8n.pt source="0"
注 : 上記のコマンドを実行した際にエラーが発生する場合には、コマンドの末尾にdevice=0を加えてみてください。

TensorRTを使用して推論速度を向上させる
上で既に述べたように、Jetson上でYOLOv8モデルの推論速度を向上させるためには、PyTorchモデルをTensorRTモデルに変換することが必要です。
以下を参照してYOLOv8 PyTorchモデルをTensorRTモデルに変換してください。
注 :
上記の4種類全ての推論モデルに適用できます。
Step 1. モデルパスを設定してエクスポートコマンドを実行する
yolo export model=<path_to_pt_file> format=engine device=0
例 :
yolo export model=yolov8n.pt format=engine device=0
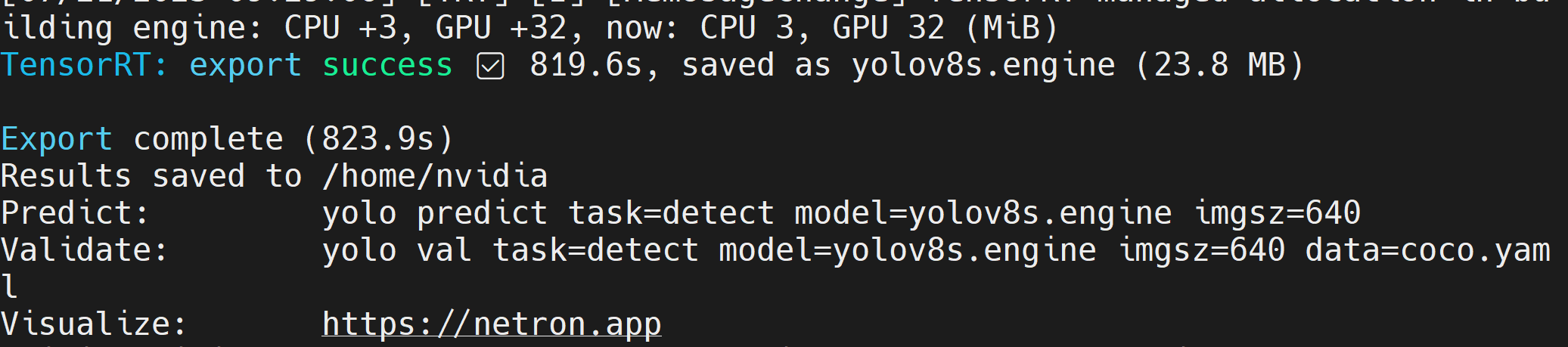
注 : cmakeエラーは無視できます。TensorRTのエクスポートには時間がかかる場合があります。
TensorRTモデルファイル(.engine)が生成されると以下のように表示されます。
Step 2. 追加の引数を渡したい場合には、以下の表を参考にしてください。
| キー | 値 | 説明 |
|---|---|---|
| imgsz | 640 | 画像サイズ(スカラーもしくはh,wで表されたリスト)例 :(640, 480) |
| half | False | FP16量子化 |
| dynamic | False | Dynamic axes |
| simplify | False | モデルの簡略化 |
| workspace | 4 | ワークスペース容量(GB) |
例えば、PyTorchモデルをFP16量子化してTensorRTモデルに変換したい場合、以下のコードを実行します。
yolo export model=yolov8n.pt format=engine half=True device=0
モデルのエクスポートが成功したあとは、yoloのpredictコマンド内のmodel=引数をこのモデルに直接置き換えて使用できます。検知、分類、セグメンテーション、姿勢推定の4種類全てのタスクに使用できます。
例えばオブジェクト検知の場合には以下のように記述します。
yolo detect predict model=yolov8n.engine source='0' show=True
独自のAIモデルを使用する
データの収集とラベリング
AIを使用した特定の事例に、その事例に適した独自のAIモデルを使用したい場合、YOLOv8を使用して、独自のデータセットの収集やラベリング、トレーニングを行うことができます。
自分でデータ収集をしたくない場合には、公開されているデータセットを選んで使用することもできます。COCOデータセット、Pascal VOCデータセットなど、公開されているさまざまなデータセットをダウンロード可能です。マシンビジョンモデルの構築に利用できる幅広い種類のデータセットを有し、Pascal VOCデータセットを提供しているRoboflow Universeはおすすめのプラットフォームです。Googleでオープンソースのデータセットを検索し、配布されているデータセットの中から選んで使用することもできます。
自分で収集したデータセットの画像にアノテーションを行いたい場合には、SeeedではRoboflowから提供されているアノテーション用ツールの使用をおすすめしています。詳細は該当するWikiのセクションを参考にしてください。Roboflowのアノテーションに関するガイドもあります。
トレーニング
モデルのトレーニングには以下の3種類の方法があります。
1. Ultralytics HUBを使用する方法 : RoboflowはUltralytics HUBに簡単に組み合わせることができ、トレーニング用のRoboflowプロジェクトをすぐに使用できます。すぐにトレーニングを始められ、トレーニングのプロセスをリアルタイムで確認できるGoogle Colabドキュメントが提供されています。
2. Seeedが作成したGoogle Colabワークスペースを使用する方法 : RoboflowプロジェクトからのデータセットのダウンロードにはRoboflow APIを使用しています。
3. ローカルPCを使用する方法 : 充分な性能のGPUが必要です。データセットは手動でダウンロードする必要があります。
Ultralytics HUB、Roboflow、Google Colabを使用する場合
この方法ではRoboflowプロジェクトをUltralyticsに読み込み、Google Colabを使用してトレーニングを行います。
-
Step 1. リンクからUltralyticsアカウントの登録を行います。
-
Step 2. アカウントの登録が完了すると、以下のようなダッシュボード画面が表示されます。
-
Step 3. リンクからRoboflowアカウントの登録を行います。
-
Step 4. アカウントの登録が完了すると、以下のようなダッシュボード画面が表示されます。
-
Step 5. SeeedのWikiガイドに従って、Workspacesメニューから新規ワークスペースを作成します。Roboflowの公式ドキュメントの記事も参考にしてください。
-
Step 6. ワークスペースにプロジェクトが追加されると、以下のように表示されます。
-
Step 7. SettingsメニューからRoboflow APIを選択してクリックします。
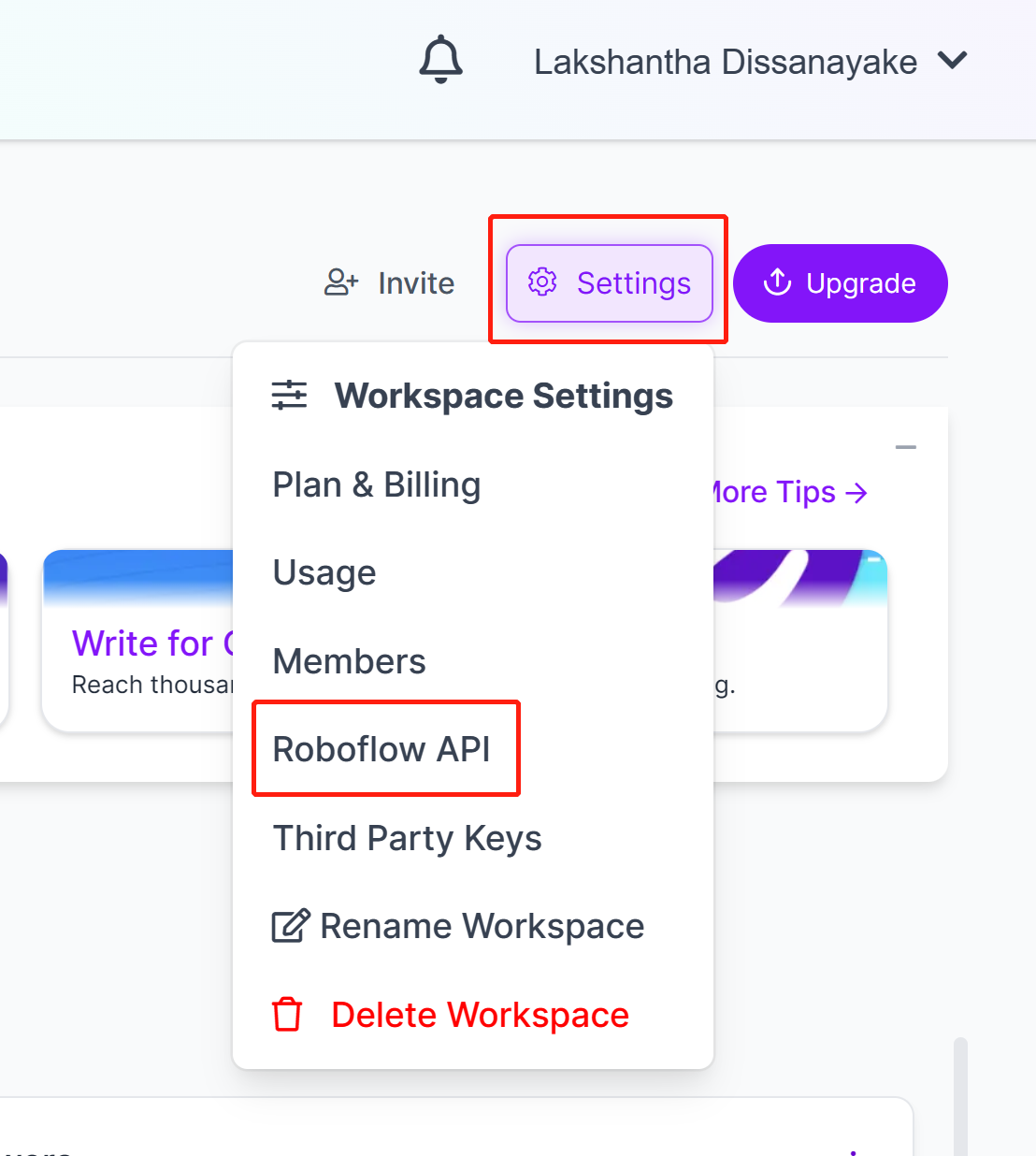
-
Step 8. CopyボタンをクリックしてPrivate API Keyをコピーします。
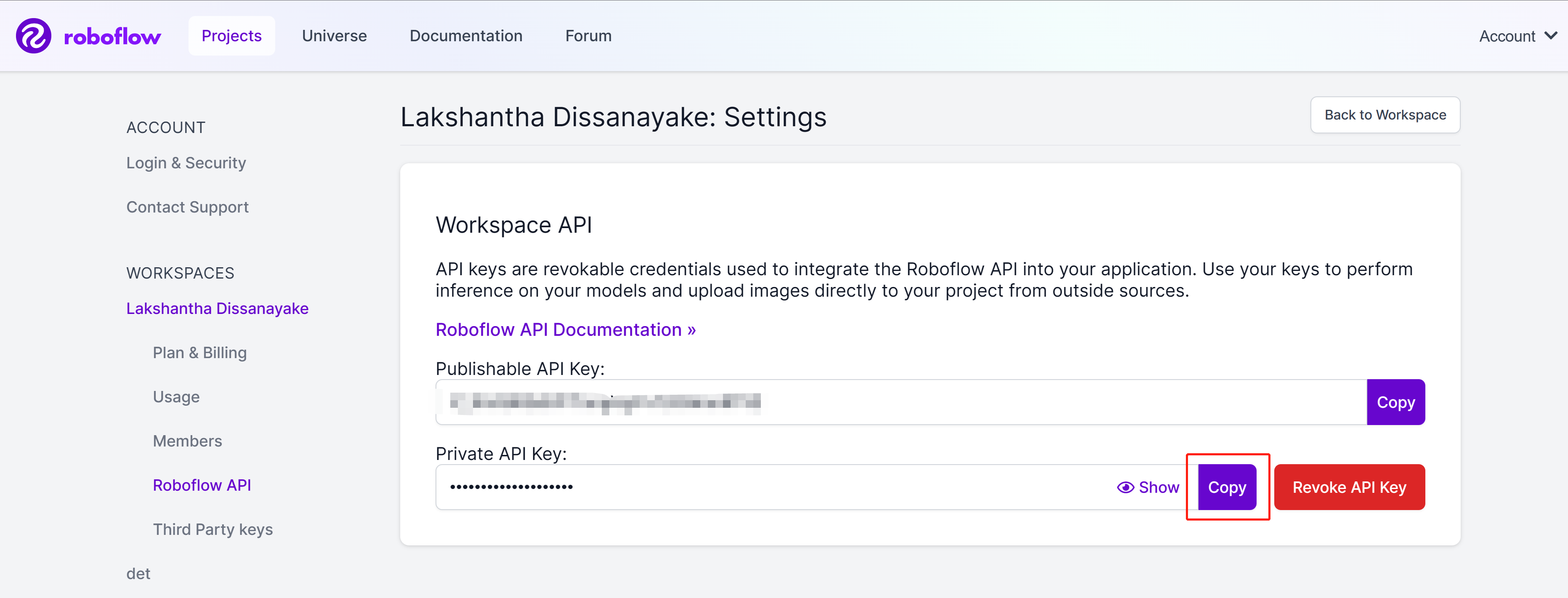
-
Step 9. Ultralyticsのダッシュボード画面に戻り、Integrationsをクリックします。コピーしたAPIキーを空欄にペーストし、Addをクリックします・
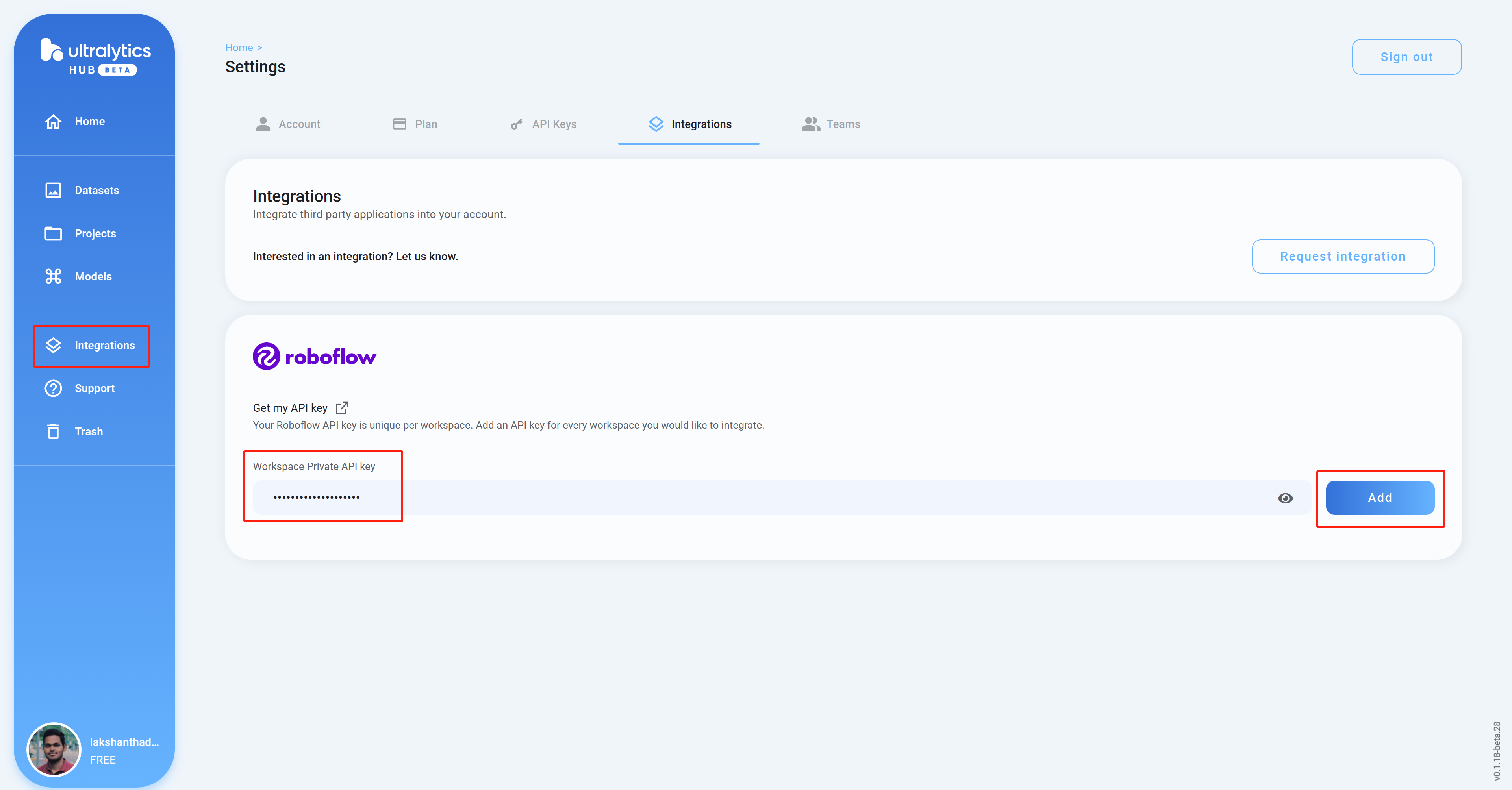
-
Step 10. ワークスペース名が表示されたら、読み込みは正常に行われています。
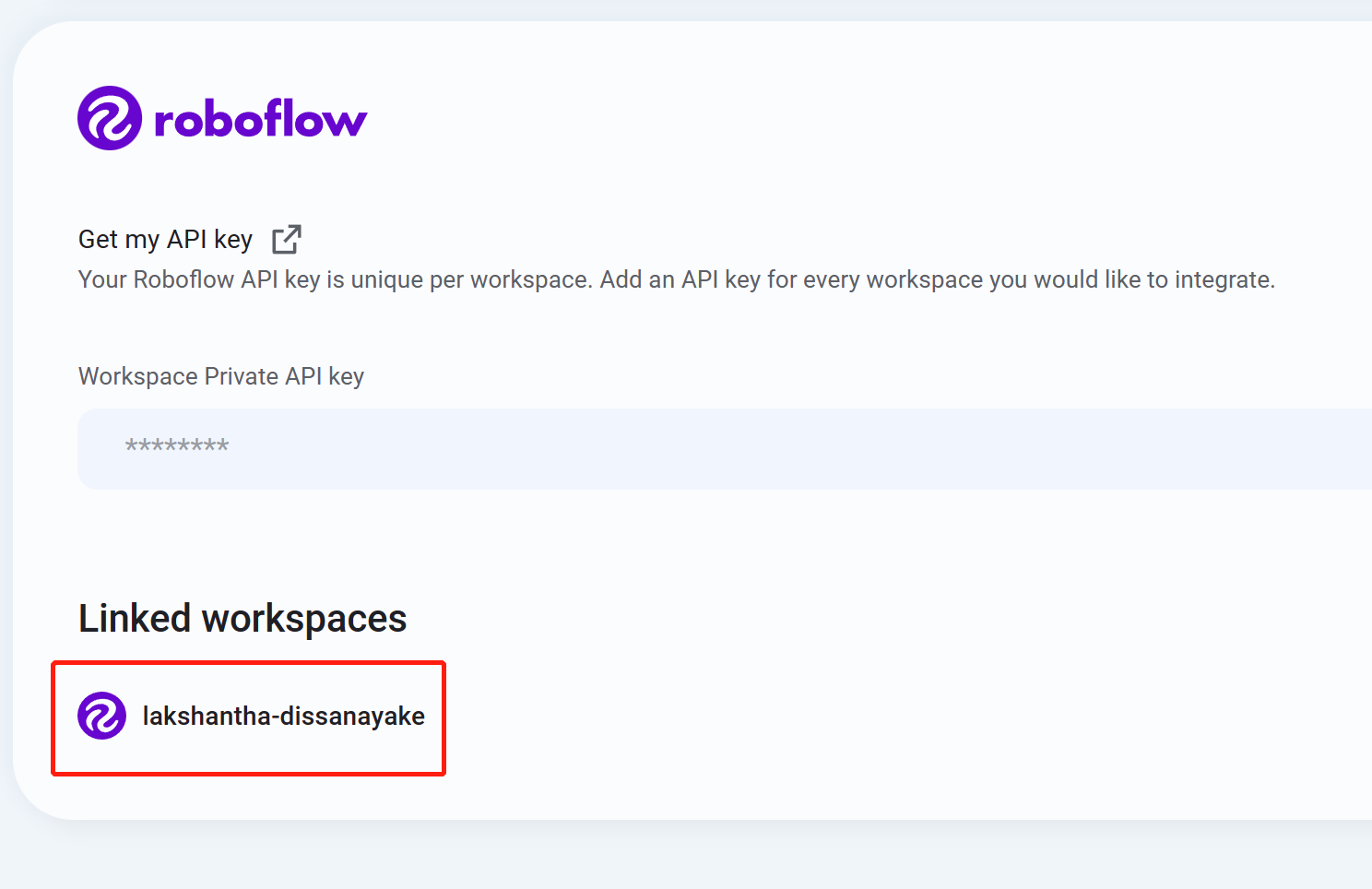
-
Step 11. Datasetsメニューに移動すると、読み込んだRoboflowプロジェクトを確認できます。
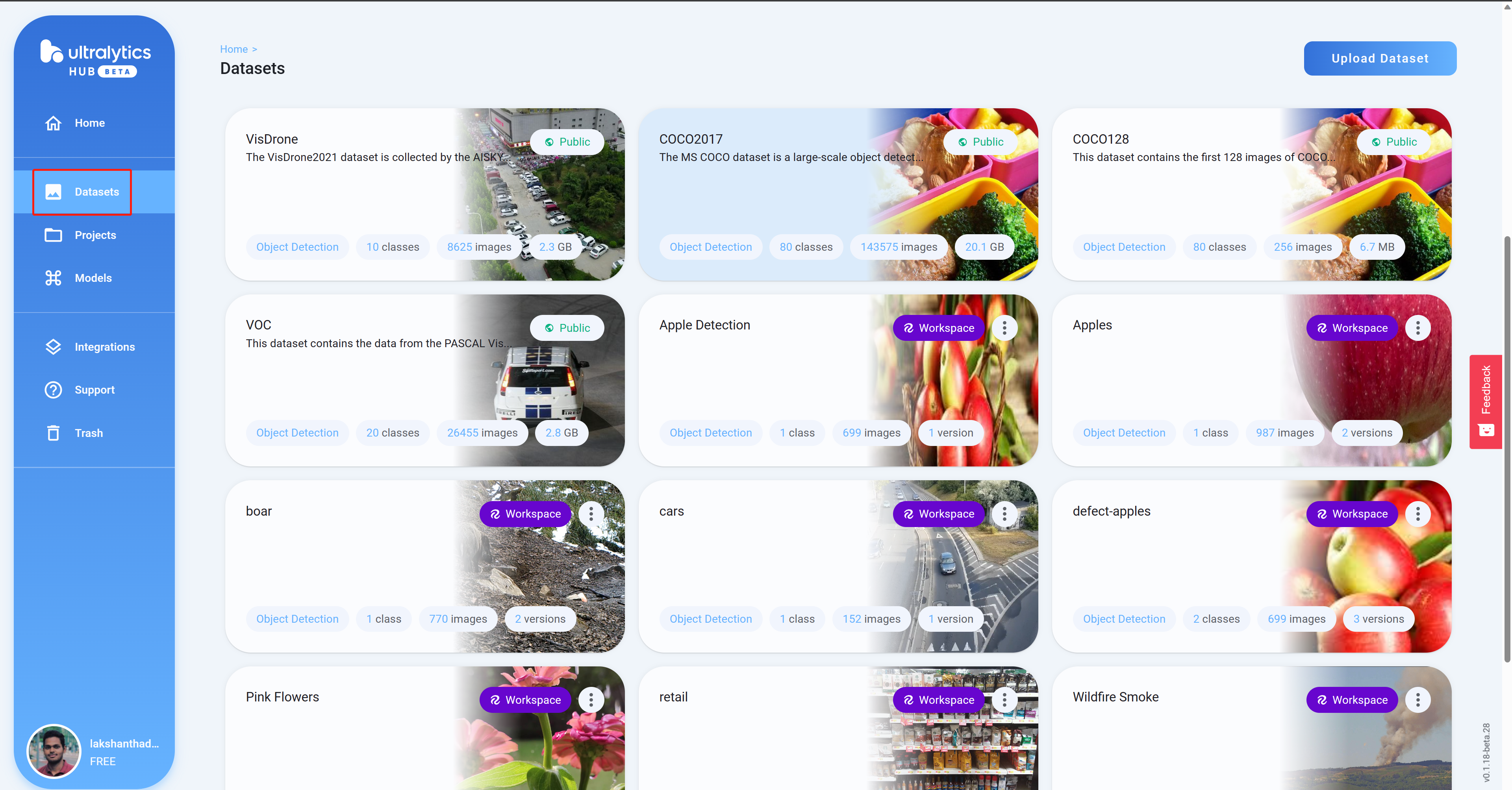
-
Step 12. プロジェクトをクリックするとデータセットの詳細を確認できます。下の画像は、新鮮なリンゴと傷んだリンゴの区別に使用するデータセットを選択したところです。
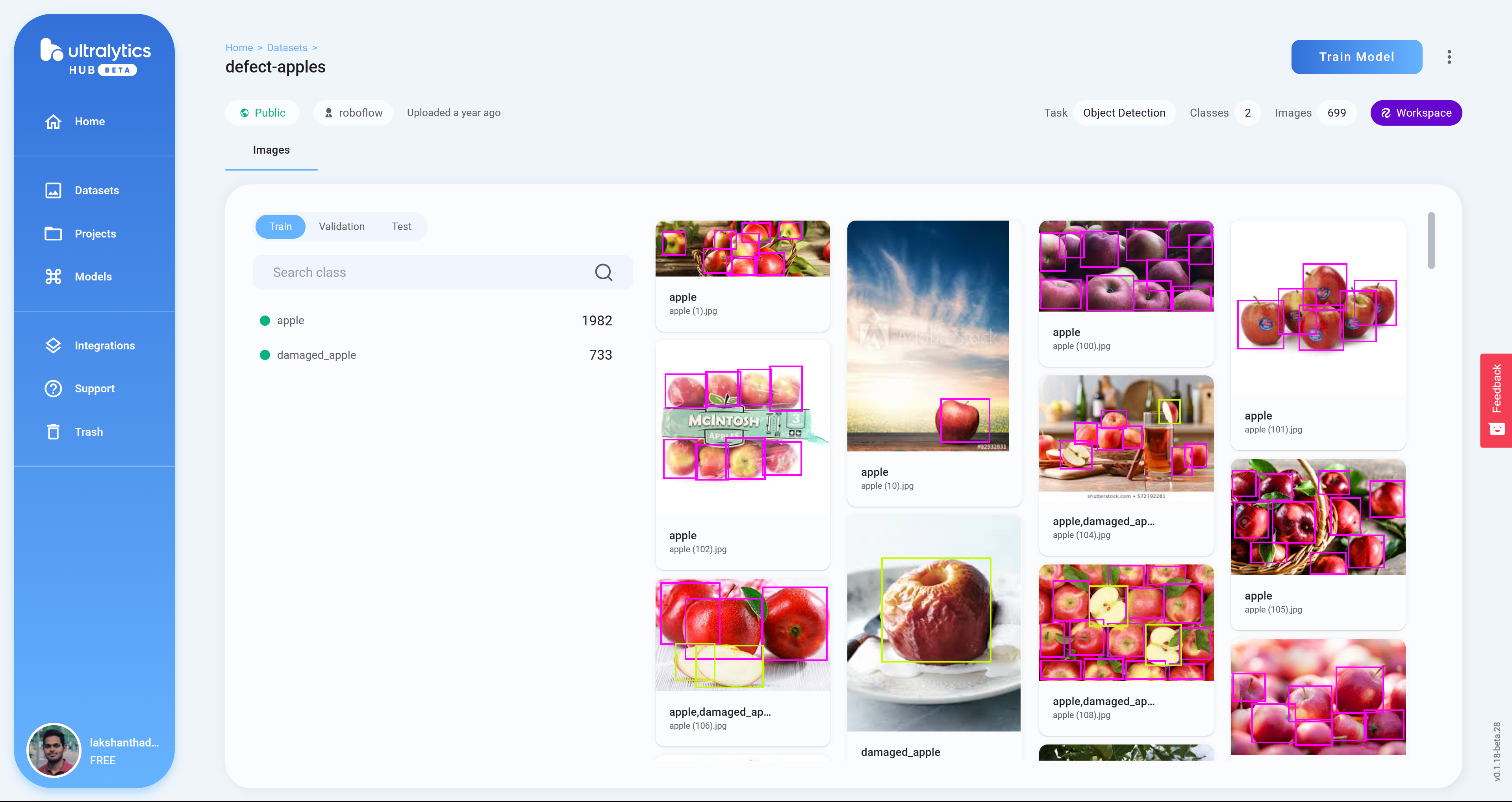
-
Step 13. Train Modelをクリックします。
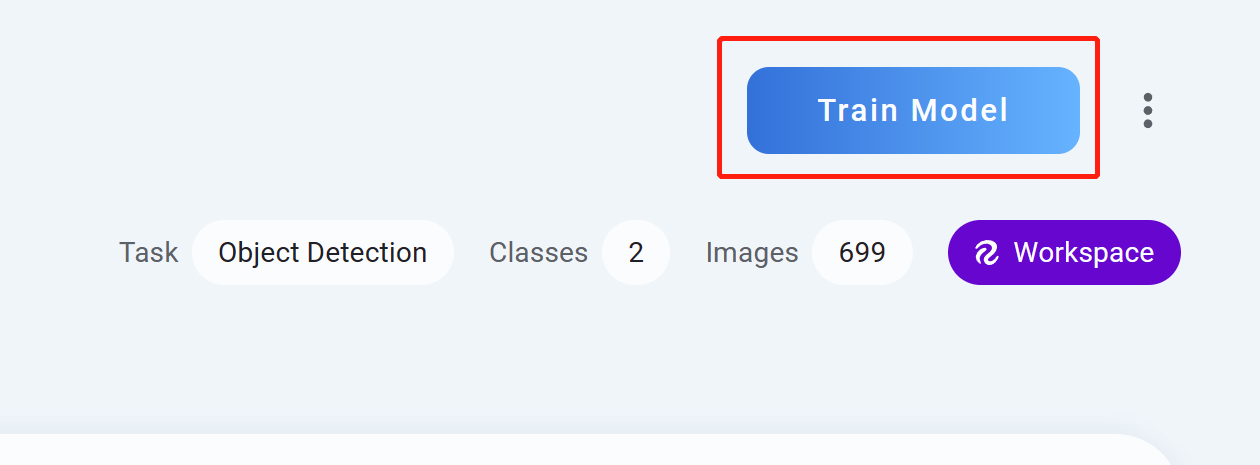
-
Step 14. Architectureを選択してモデル名(オプション)を設定し、Continueをクリックします。下の画像では、モデルアーキテクチャにYOLOv8sを選択しています。
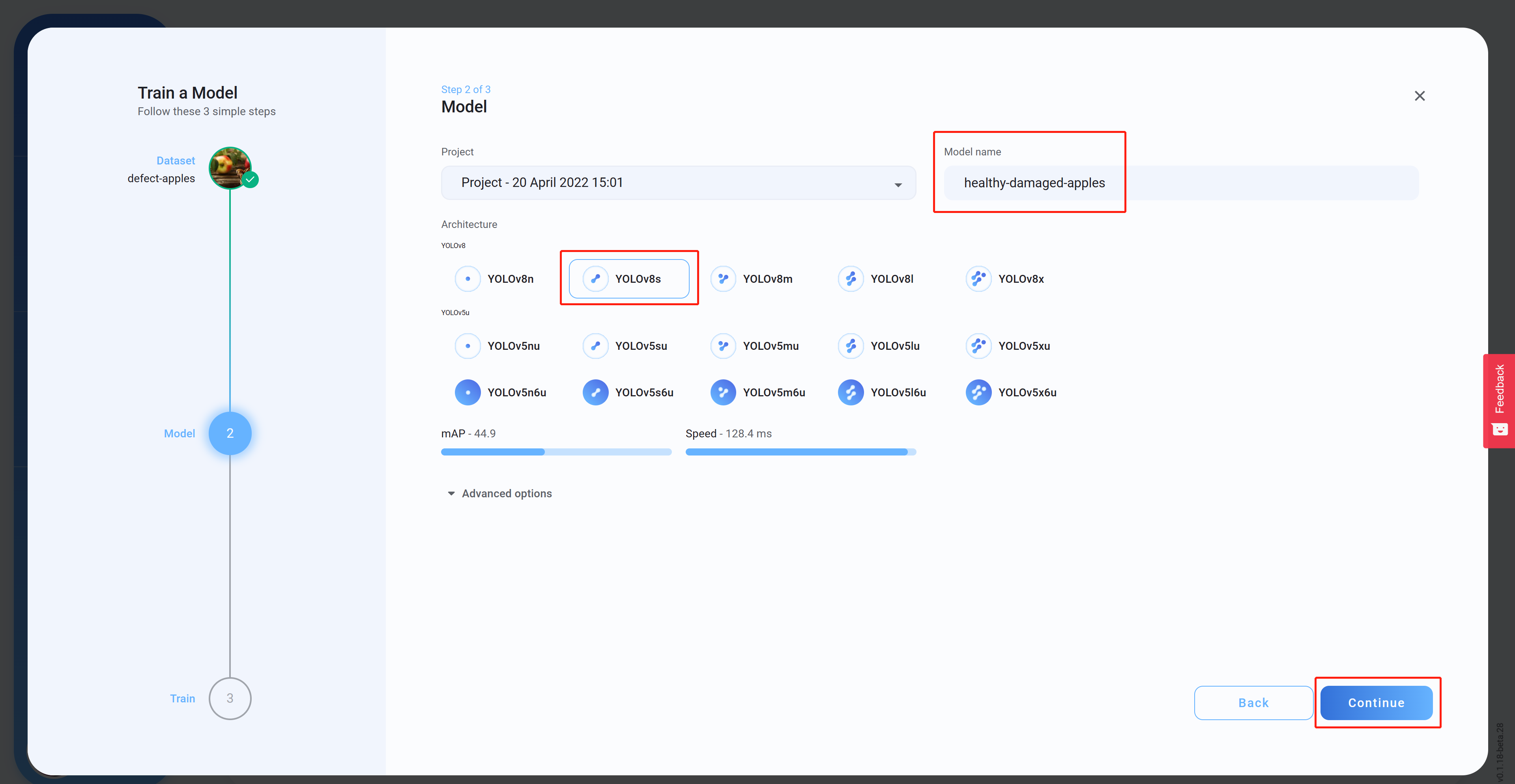
-
Step 15. Advanced Optionsから用途に合った設定を行い、Colabコードをコピーします。このコードは後ほどColabワークスペース上でペーストします。Open Google Colabをクリックします。
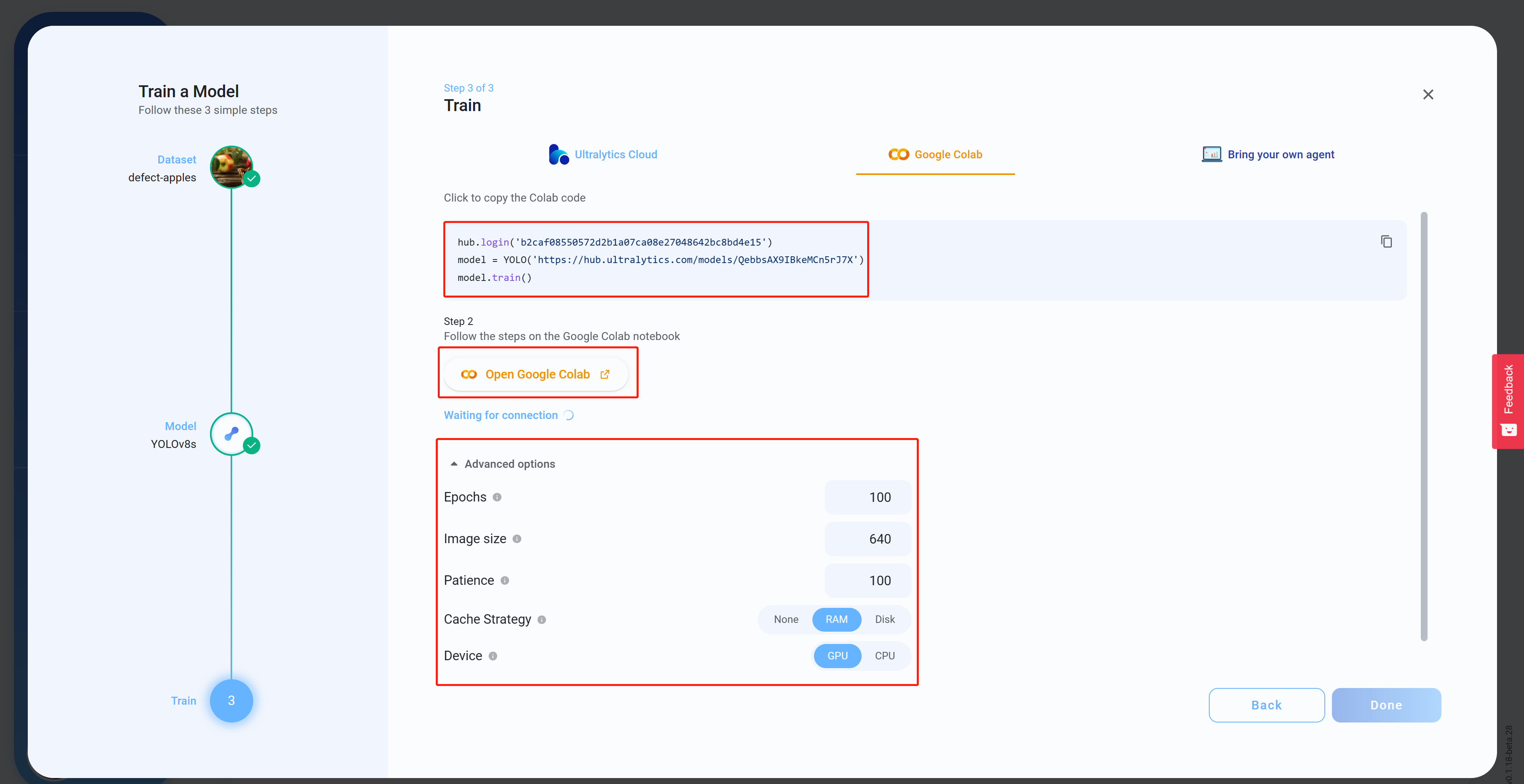
-
Step 16. Googleアカウントにサインインします。
-
Step 17
Runtime > Change runtime typeと進みます。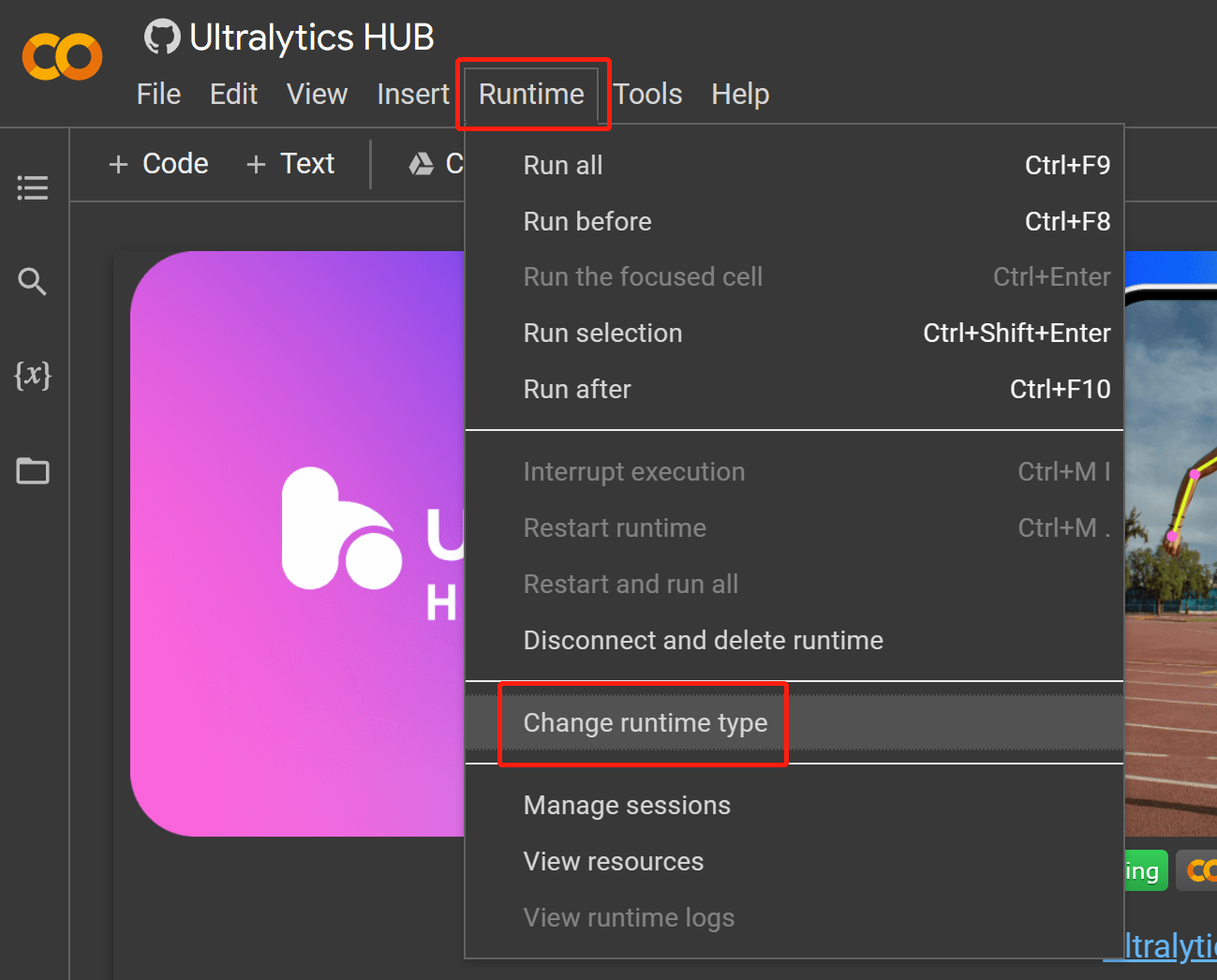
-
Step 18. Hardware acceleratorからGPUを選択し、GPU typeに表示されているうち一番上のものを選択してSaveをクリックします。
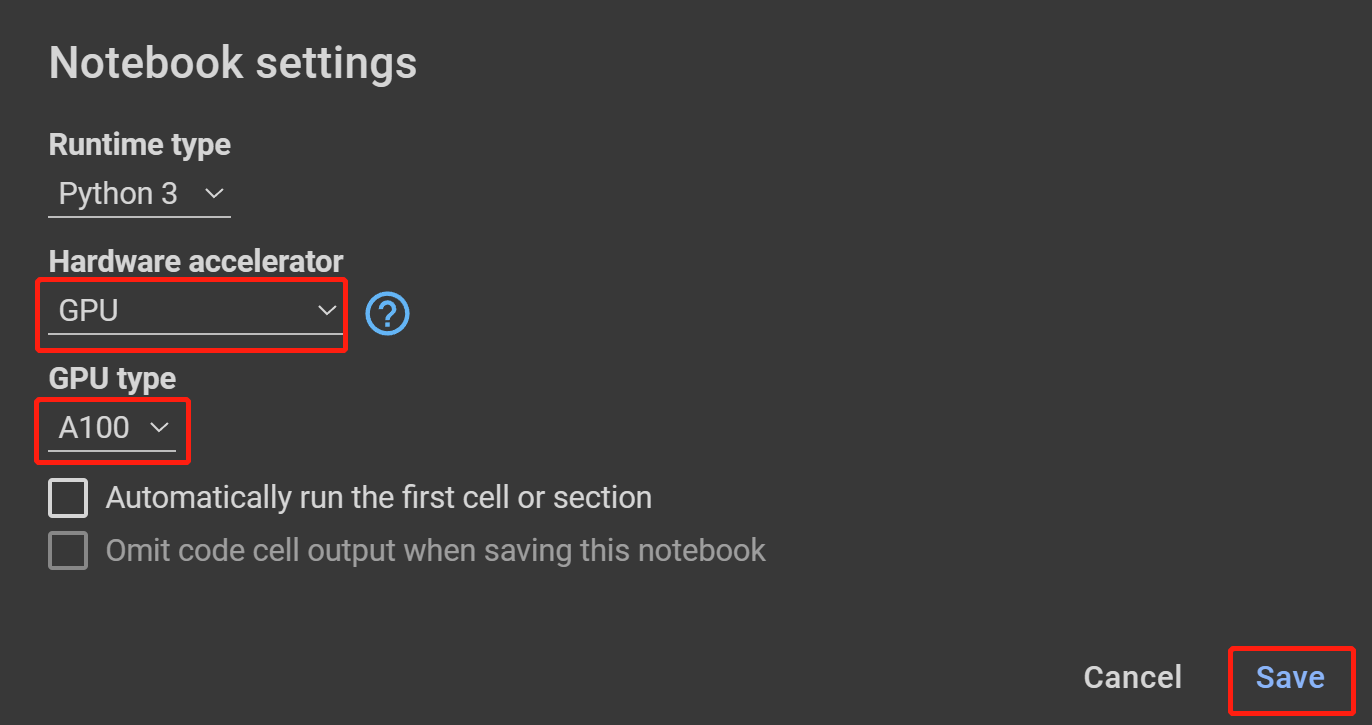
-
Step 19. Connectをクリックします。
-
Step 20. RAM、Diskをクリックして、ハードウェアリソースを確認します。
-
Step 21. Playをクリックして最初のコードセルを実行します。
-
Step 22. Ultralytics HUBからコピーしてきたコードセルをStartセクションの下にペーストし、トレーニングを開始します。
-
Step 23. Ultralytics HUBに戻り、Connectedと表示されていることを確認してください。Doneをクリックします。
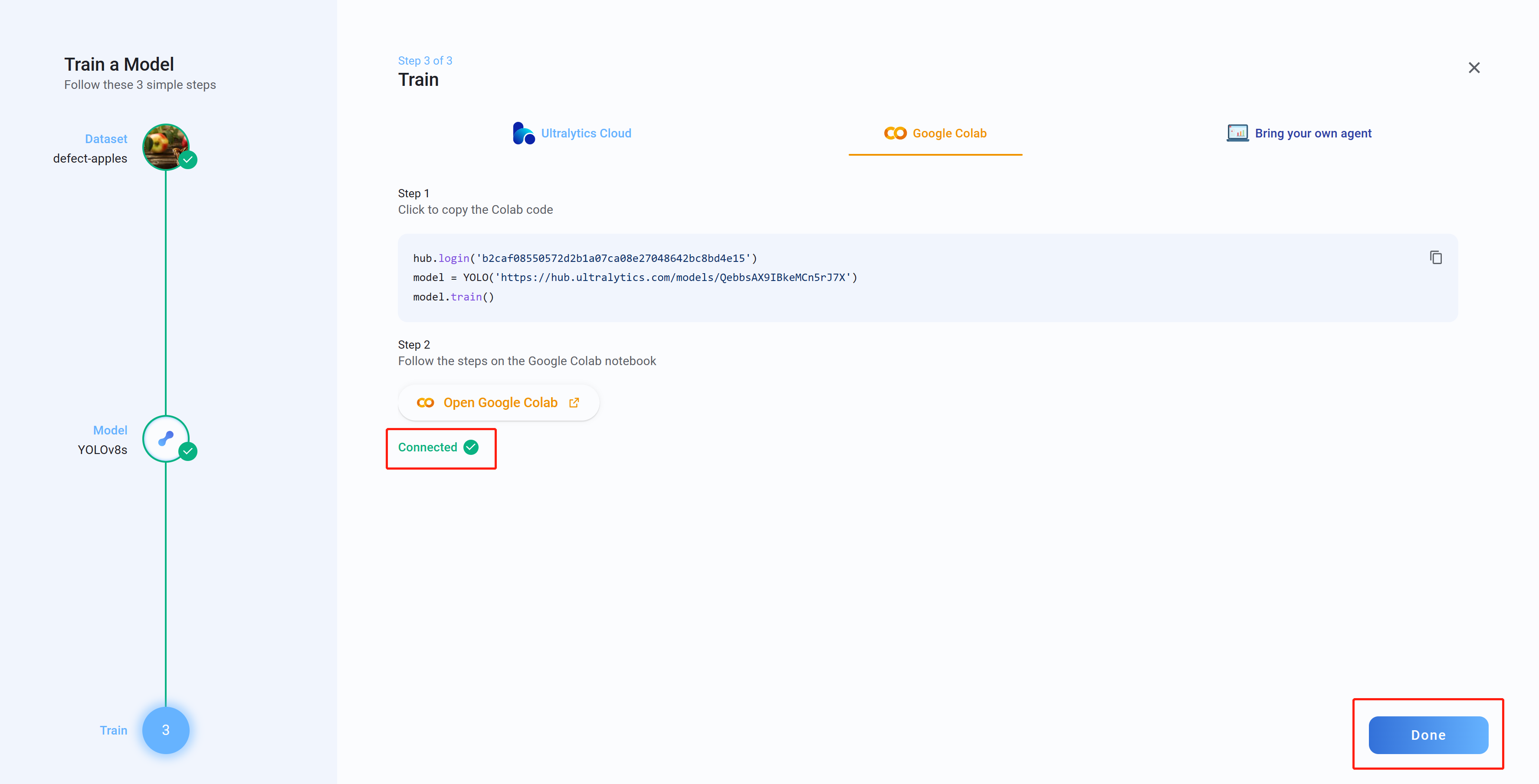
-
Step 24. モデルのトレーニングが進むにつれ、Google ColabにBox Loss、Class Loss、Object Lossがリアルタイムに表示されるようになりました。
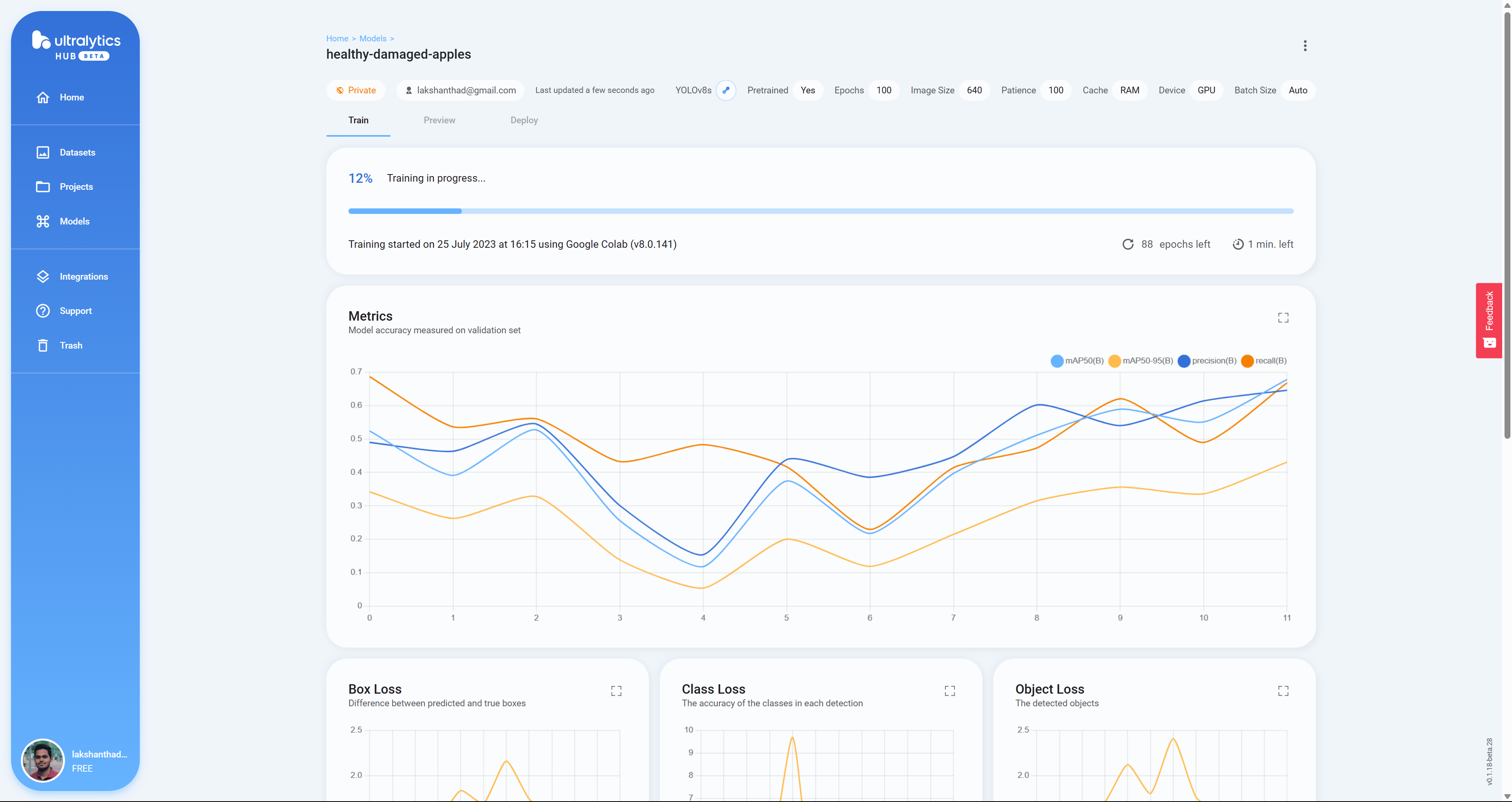
-
Step 25. トレーニングが完了すると、Google Colabに以下のようなアウトプットが表示されます。
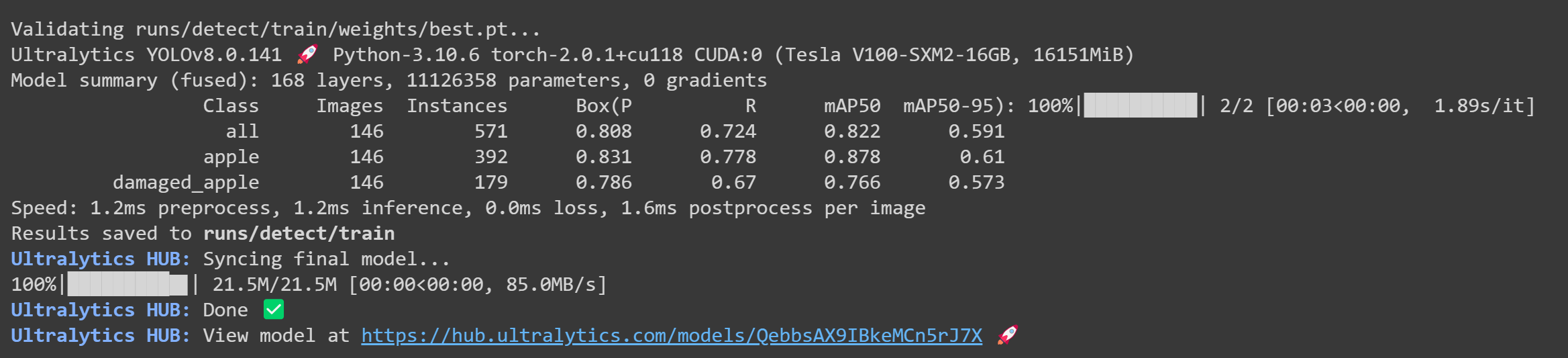
-
Step 26. トレーニングモデルの結果を確認するには、Ultralytics HUBに戻り、Previewタブからテスト画像のアップロードを行ってください。
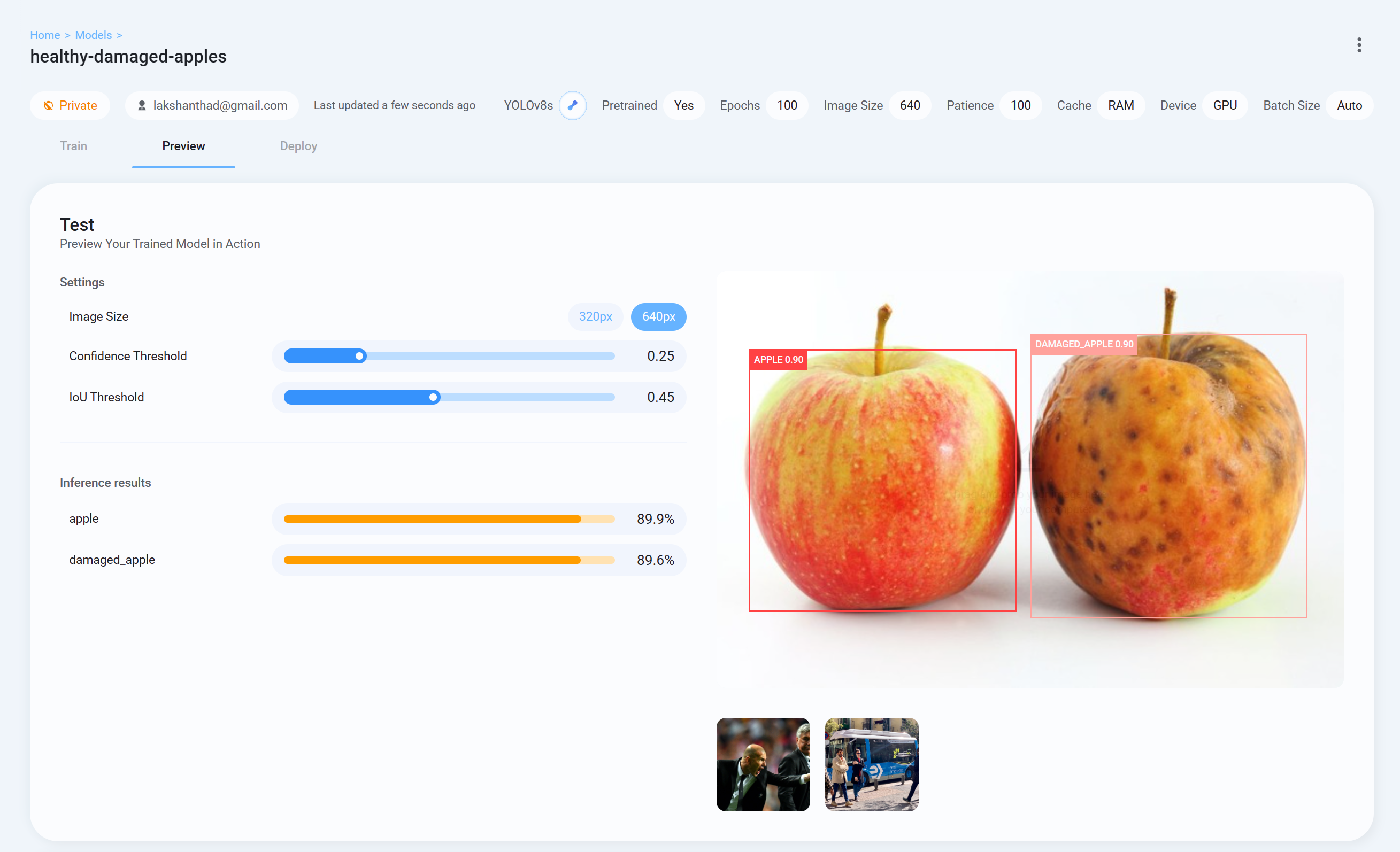
-
Step 27. 必要なフォーマットのトレーニングモデルのダウンロードはDeployタブから行えます。下の画像ではPyTorchを選択しています。
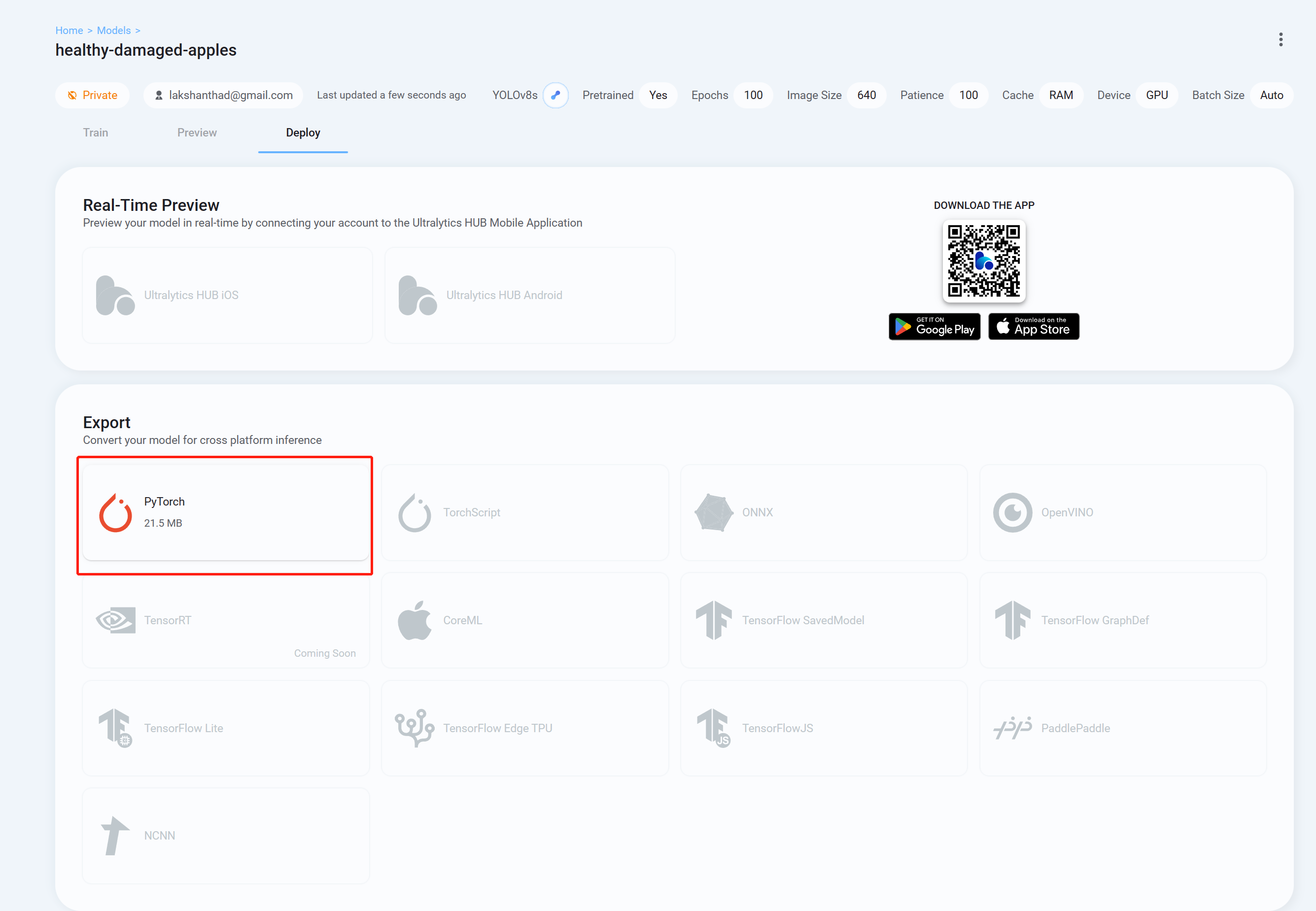
ダウンロードしたトレーニングモデルは、wikiの前の方で説明したようなタスクに使用することができます。モデルファイルをダウンロードしたモデルファイルに置き換えて使用してください。
例:
yolo detect predict model=<your_model.pt> source='0' show=True
RoboflowとGoogle Colabを使用する場合
クラウド上でのトレーニングにGoogle Colaboratory環境を使用します。また、Colab上でRoboflow apiを使用することで、Seeedのデータセットを簡単にダウンロードできます。
- Step 1. こちらをクリックして提供されているGoogle Colabワークスペースを開き、ワークスペース内のステップに従ってトレーニングを進めます。
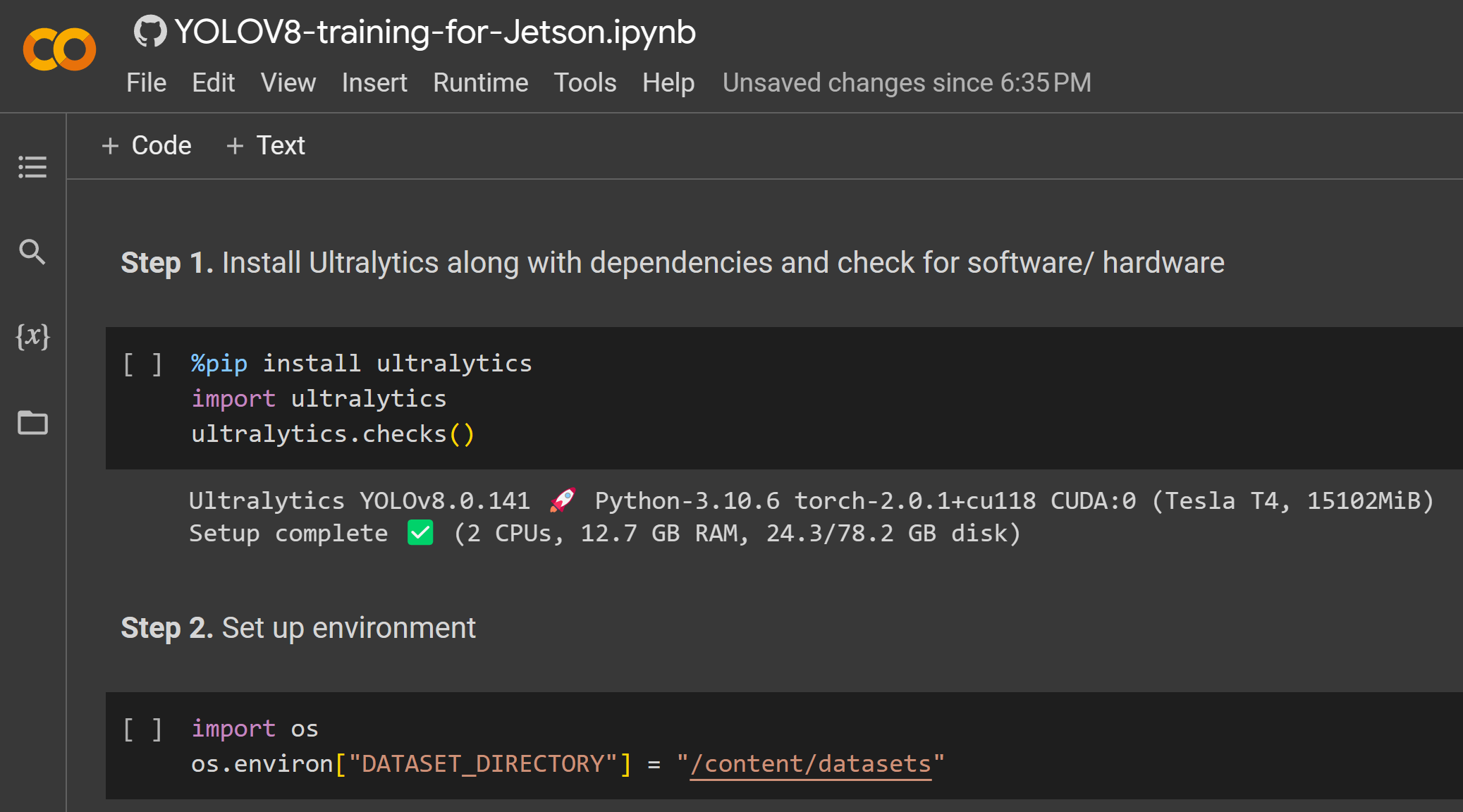
トレーニングが完了すると以下のようなアウトプットが表示されます。
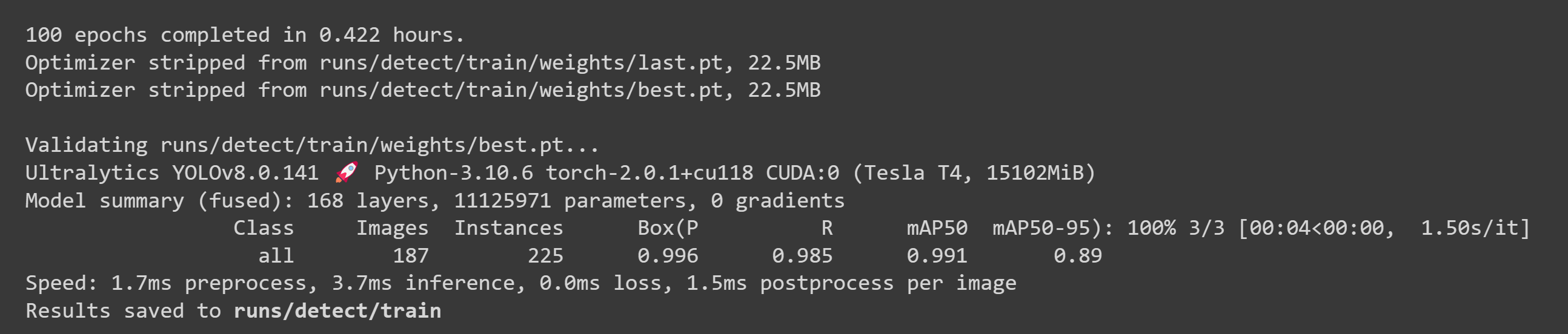
- Step 2. Filesタブからruns/train/exp/weightsと進み、best.ptというファイルを探してください。これがトレーニングによって生成されたモデルです。後ほど推論に使用するので、ファイルをダウンロードし、お使いのJetsonデバイスにコピーしてください。
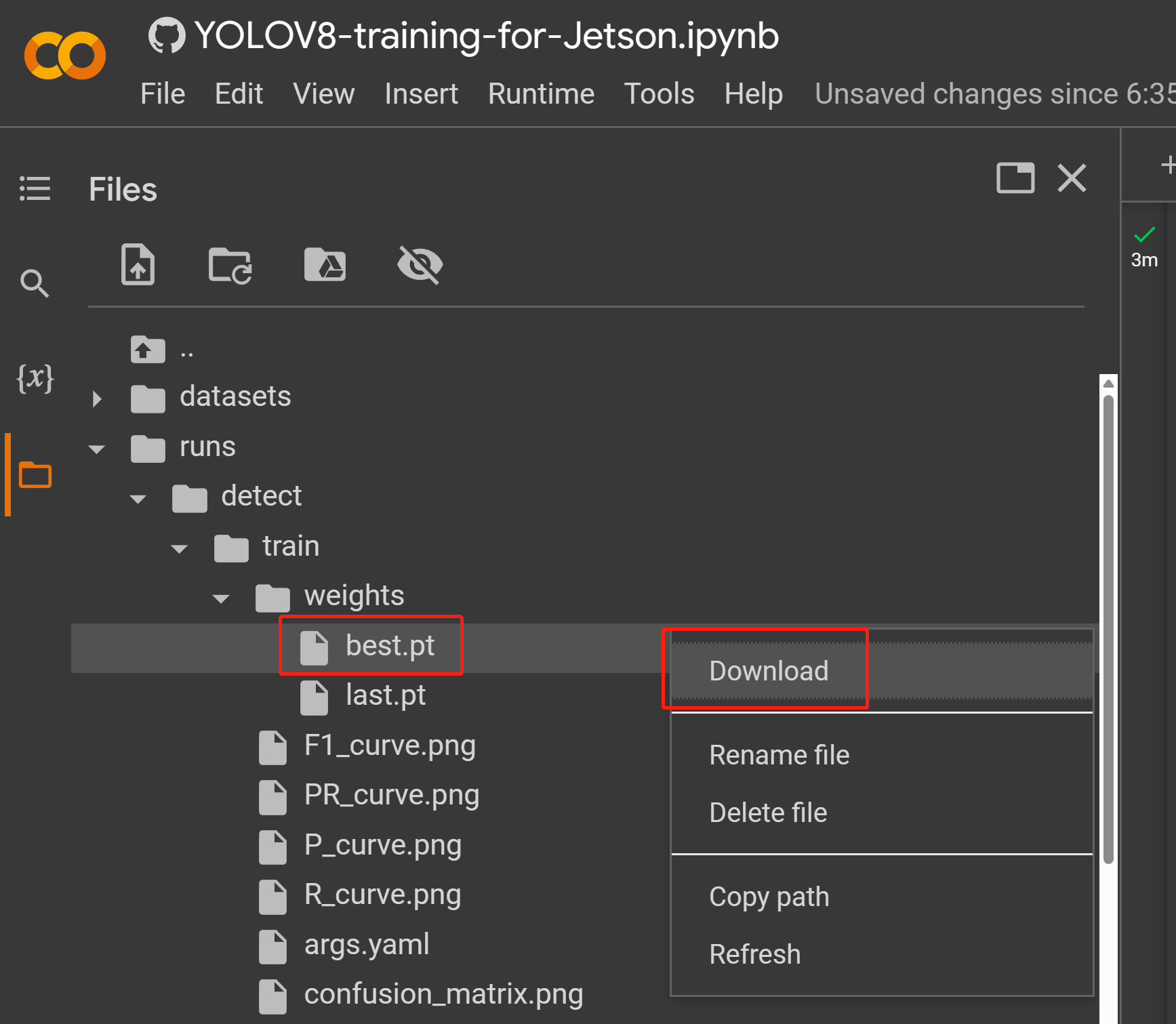
ダウンロードしたトレーニングモデルは、wikiの前の方で説明したようなタスクに使用することができます。モデルファイルをダウンロードしたモデルファイルに置き換えて使用してください。
例:
yolo detect predict model=<your_model.pt> source='0' show=True
RoboflowとローカルPCを使用する場合
Linux OSをインストールしたPCを使用してトレーニングを行います。本wikiではUbuntu 20.04 PCを使用しています。
- Step 1. pipがインストールされていない場合はpipのインストールを行います。
sudo apt install python3-pip -y
- Step 2. Ultralyticsと関連ファイルをインストールします。
pip install ultralytics
-
Step 3. RoboflowのプロジェクトタブからVersionsメニューへ進み、Export Datasetをクリックします。FormatにYOLOv8を選択し、Download zip tocomputerにチェックを入れてContinueをクリックします。
)
-
Step 4. ダウンロードしたzipファイルを解凍します。
-
Step 5. 下のコードを実行してトレーニングを開始します。path_to_yaml部分はzipファイル内の.yamlファイルのパスを参照するようにしてください。
yolo train data=<path_to_yaml> model=yolov8s.pt epochs=100 imgsz=640 batch=-1
注 : 画像サイズは640 x 640に設定されています。適したバッチサイズを自動判別するため、バッチサイズは-1に設定されています。用途に合わせて値は変更できます。事前トレーニングモデルはトレーニングモデルに合わせて変更を行ってください。
トレーニングが完了すると以下のようなアウトプットが表示されます。
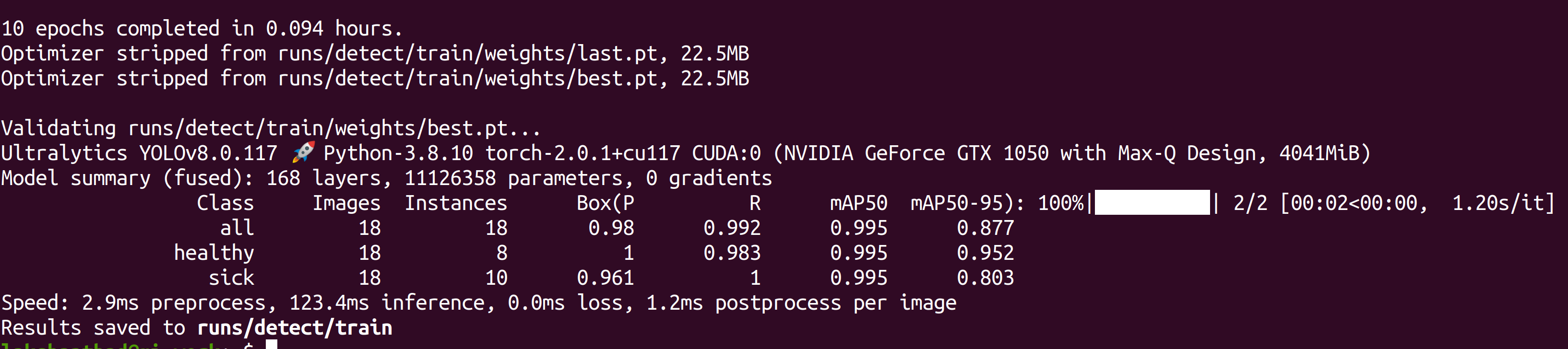
- Step 6. runs/detect/train/weightsからbest.ptファイルを探してください。これがトレーニングによって生成されたモデルです。後ほど推論に使用するので、ファイルをダウンロードし、お使いのJetsonデバイスにコピーしてください。

例 :
yolo detect predict model=<your_model.pt> source='0' show=True
パフォーマンスベンチマーク
準備
Seeedでは、NVIDIA Jetson Orin NX 16 GBベースのreComputer J4012及びreComputer Industrial J4012でYOLOv8を動作させ、全てのマシンビジョンタスクのパフォーマンスベンチマークを行っています。
サンプルディレクトリにはコマンドラインラッピングツール trtexecが含まれています。自身でアプリケーションの開発を行うことなくTensorRTを使用するためのツールです。trtexecツールには以下のような三つの機能があります。
- ランダムな入力データやユーザが用意した入力データのベンチマーク
- モデルからシリアル化されたエンジンを生成
- ビルダーからシリアル化されたタイムキャッシュを生成
この節では、異なるパラメータを有するモデルのベンチマークを簡単に行うためにtrtexecを使用します。まず最初にUltralytics YOLOv8を使用してonnxモデルを生成します。
- Step 1. onnxモデルをビルドします。
yolo mode=export model=yolov8s.pt format=onnx
- Step 2. trtexecを使用してエンジンファイルをビルドします。
cd /usr/src/tensorrt/bin
./trtexec --onnx=<path_to_onnx_file> --saveEngine=<path_to_save_engine_file>
以下は一例です。
./trtexec --onnx=/home/nvidia/yolov8s.onnx –saveEngine=/home/nvidia/yolov8s.engine
生成された.engineファイルと一緒に以下のような結果のアウトプットが得られます。デフォルトではonnxからFP32精度でTensorRTに最適化されたファイルに変換されるようになっています。以下のようなアウトプットが表示されます。
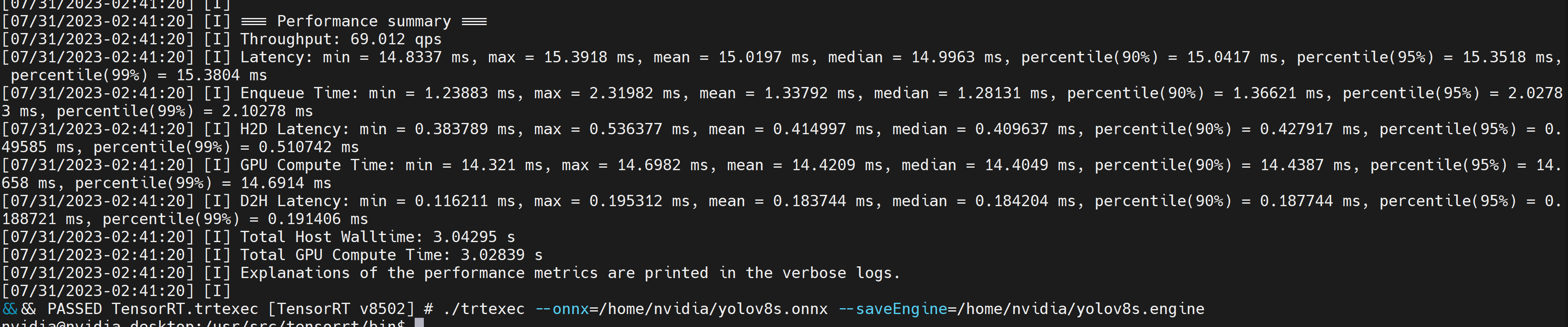
FP32よりも高いパフォーマンスのFP16精度のファイルを希望する場合には、以下のコードを使用します。
./trtexec --onnx=/home/nvidia/yolov8s.onnx --fp16 --saveEngine=/home/nvidia/yolov8s.engine
FP16よりも高いパフォーマンスのINT8精度のファイルを希望する場合には、以下のコードを使用します。
./trtexec --onnx=/home/nvidia/yolov8s.onnx --int8 --saveEngine=/home/nvidia/yolov8s.engine
結果
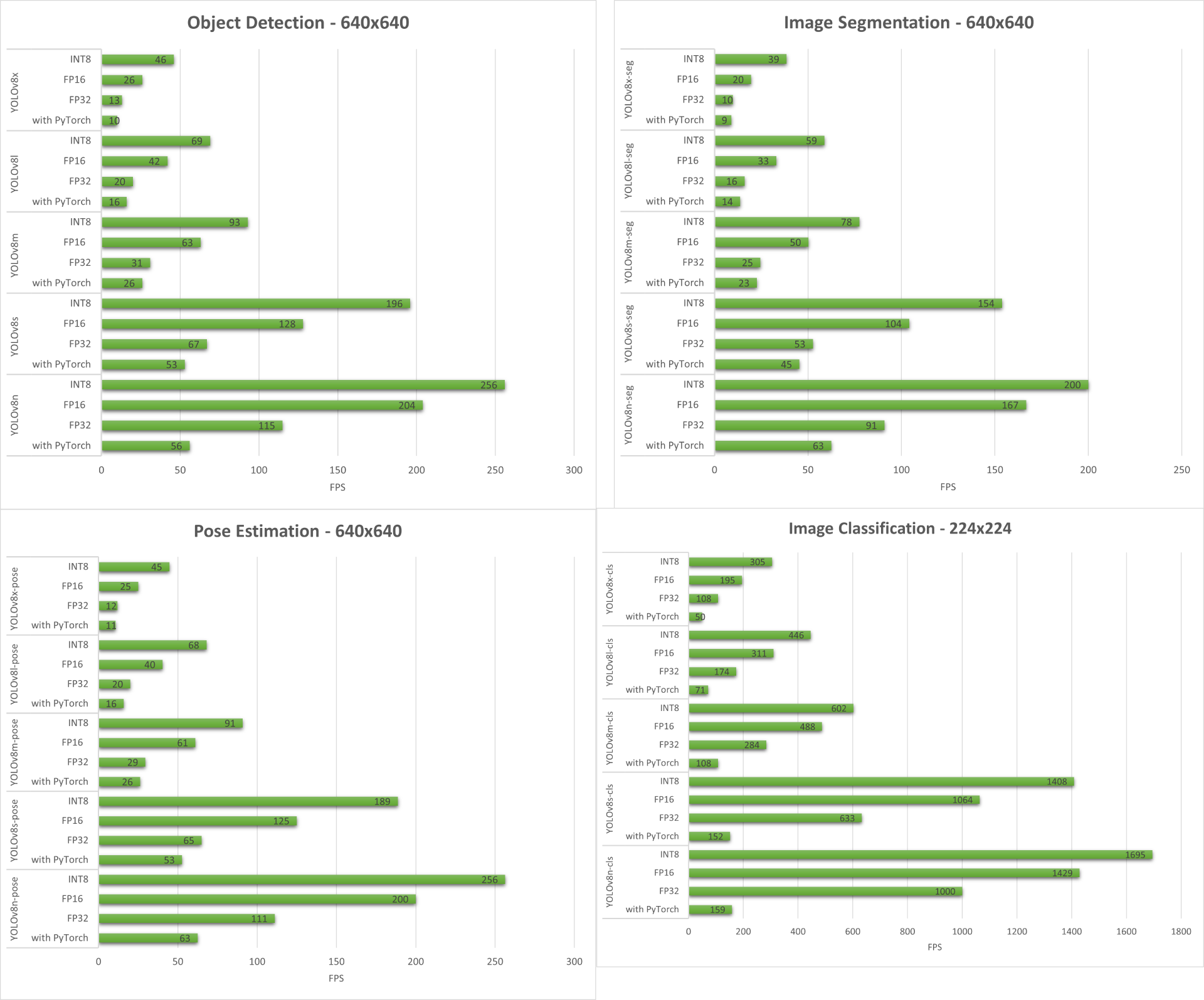
以下は、4種全てのマシンビジョンタスクをreComputer J4012及びreComputer Industial J4012で実行した際のベンチマーク結果です。
サンプルデモ : YOLOv8を使用したエクササイズ検知マシン/カウンター
以下はSeeedが作成したエクササイズ検知マシンとカウンターの姿勢推定サンプルデモです。YOLOv8-Poseモデルを使用しています。Jetsonデバイスを使用したプロジェクトの詳細はこちらからご覧いただけます。
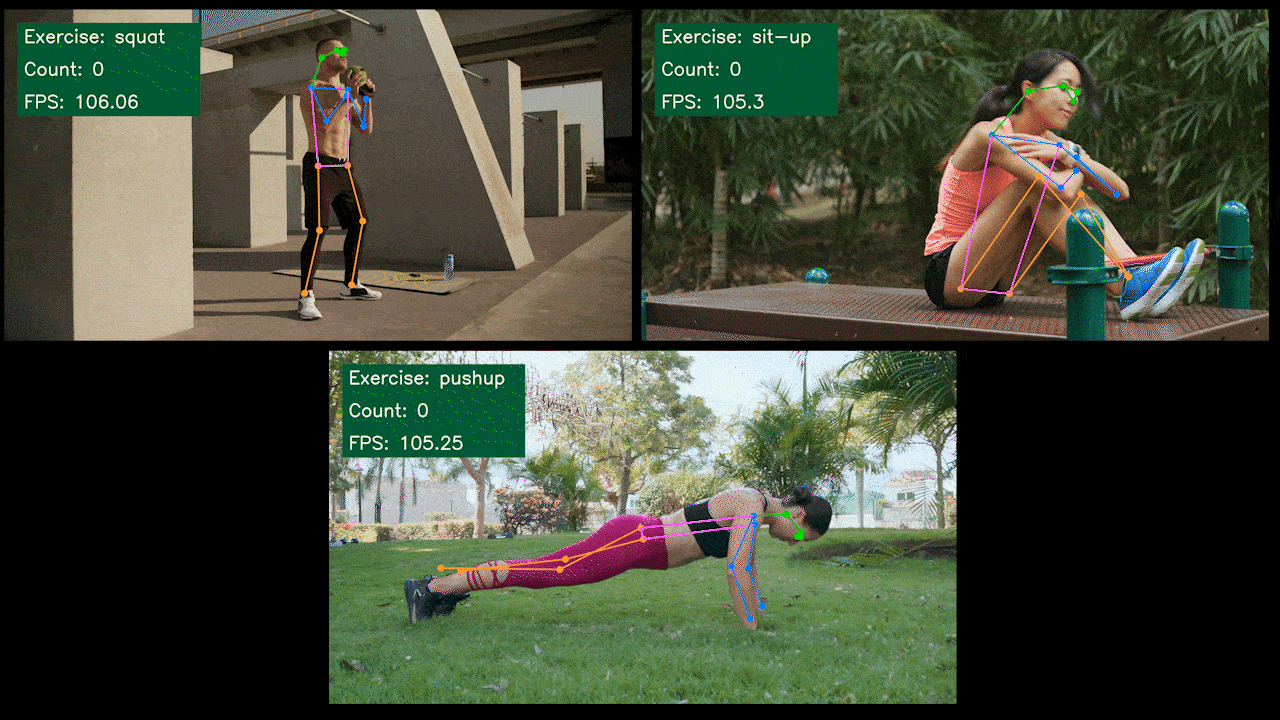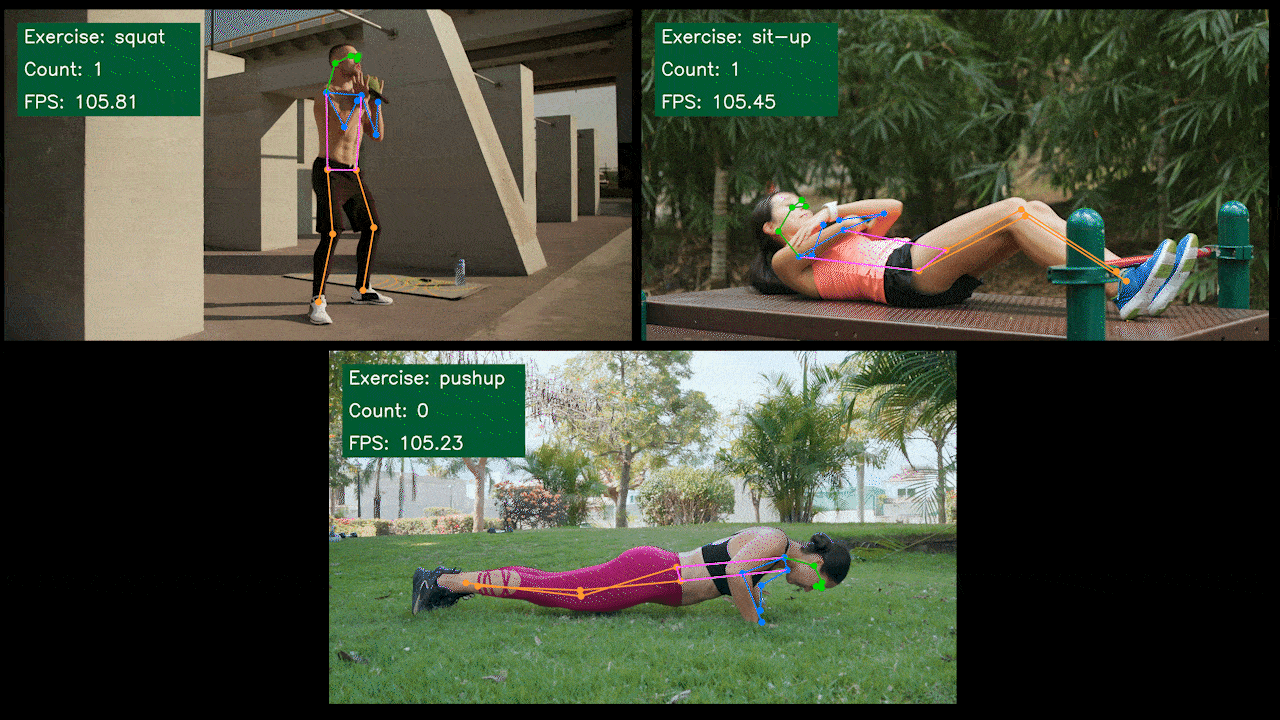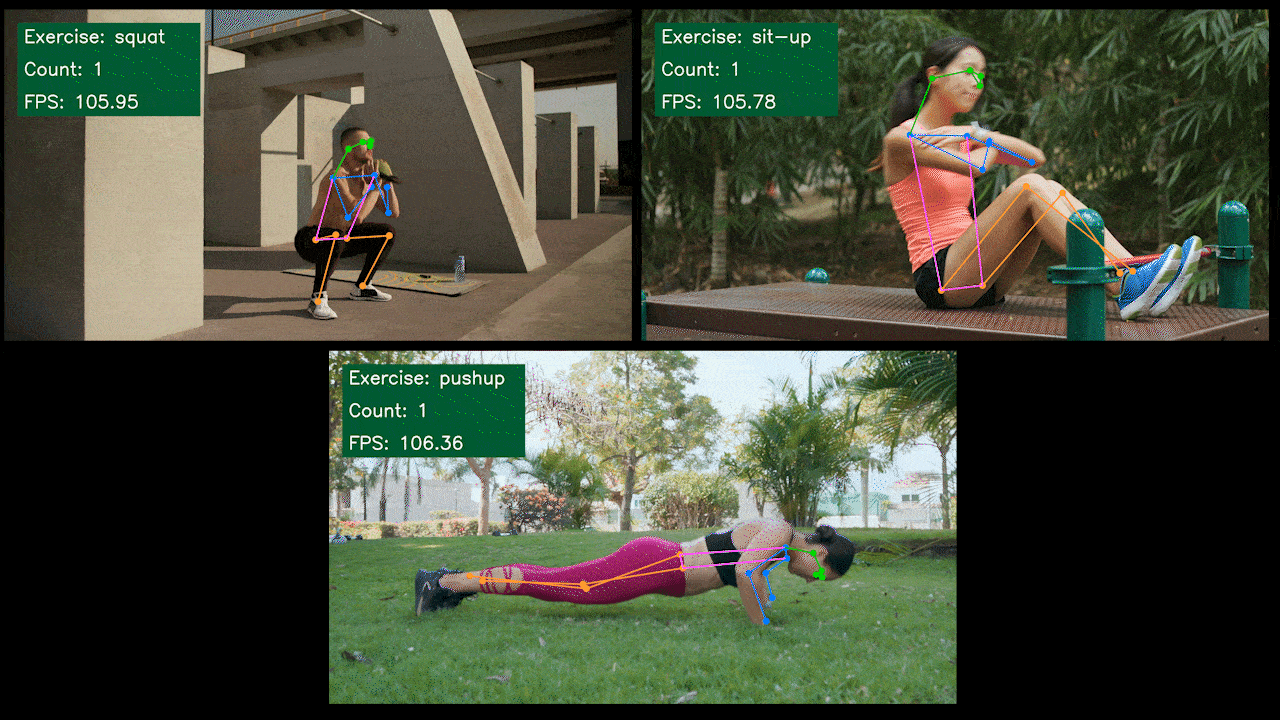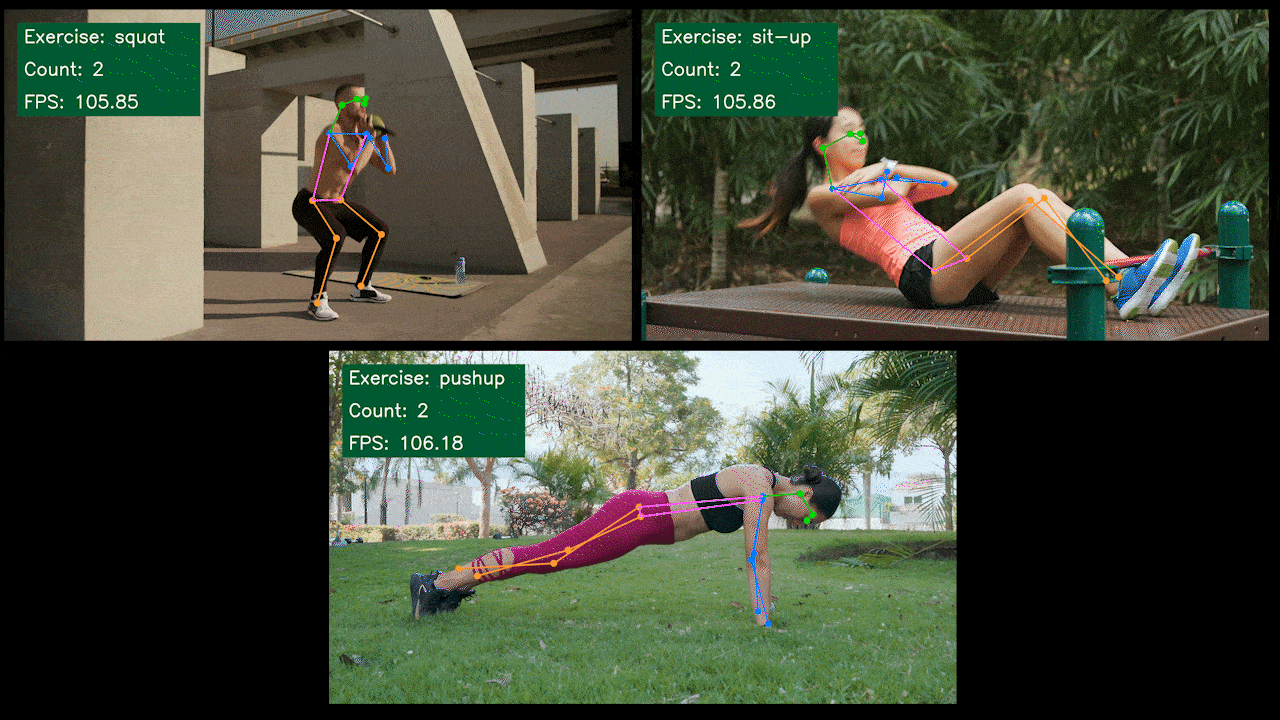
NVIDIA Jetson向けのYOLOv8のマニュアル設定
上で紹介した1行のスクリプトを使用した際にエラーが発生する場合は、以下のステップを参考にしてJetson向けのYOLOv8の設定を行なってください。
Ultralyticsパッケージのインストール
- Step 1. Jetsonデバイスでterminalを開き、pipのインストールとアップグレードを行います。
sudo apt update
sudo apt install -y python3-pip -y
pip3 install --upgrade pip
- Step 2. Ultralyticsパッケージをインストールします。
pip3 install ultralytics
- Step 3. numpyのバージョンを最新のものにアップグレードします。
pip3 install numpy -U
- Step 4. デバイスを再起動します。
sudo reboot
TorchとTorchvisionのアンインストール
上のUltralyticsのインストール方法では、TorchとTorchvisionも一緒にインストールされますが、pipを使用してインストールされたこれらのパッケージはJetsonプラットフォームとは互換性がありません。これはJetsonが**ARM AArch64アーキテクチャ**をベースにしているためです。Jetsonデバイスでの動作には、プリビルドのPyTorch pipホイールを手動でインストールし、Torchvisionをコンパイル/インストールする必要があります。
pip3 uninstall torch torchvision
PyTorchとTorchvisionのインストール
PyTorchとTorchvisionに関連するリンクはこちらのページをご覧ください。
以下はJetPack 5.0以降で対応しているバージョンの例です。
PyTorch v2.0.0
Python 3.8をインストールしたJetPack 5.1 (L4T R35.2.1) / JetPack 5.1.1 (L4T R35.3.1)
torch-2.0.0+nv23.05-cp38-cp38-linux_aarch64.whl
PyTorch v1.13.0
Python 3.8をインストールしたJetPack 5.0 (L4T R34.1) / JetPack 5.0.2 (L4T R35.1) / JetPack 5.1 (L4T R35.2.1) / JetPack 5.1.1 (L4T R35.3.1)
- Step 1.お使いのJetPackバージョンに合ったTorchのバージョンのインストールを行います。
wget <URL> -O <file_name>
pip3 install <file_name>
以下はJetPack 5.1.1で使用する場合のPyTorch v2.0.0をインストールするためのコードです。
sudo apt-get install -y libopenblas-base libopenmpi-dev
wget https://nvidia.box.com/shared/static/i8pukc49h3lhak4kkn67tg9j4goqm0m7.whl -O torch-2.0.0+nv23.05-cp38-cp38-linux_aarch64.whl
pip3 install torch-2.0.0+nv23.05-cp38-cp38-linux_aarch64.whl
- Step 2. 上でインストールしたPyTorchのバージョンに合ったTorchvisionのバージョンをインストールします。以下はPyTorch v2.0.0を使用する場合のTorchvision v0.15.2をインストールするためのコードです。
sudo apt install -y libjpeg-dev zlib1g-dev
git clone https://github.com/pytorch/vision torchvision
cd torchvision
git checkout v0.15.2
python3 setup.py install –user
以下は各PyTorchバージョンに対応したTorchvisionバージョンのリストです。
- PyTorch v2.0.0 - torchvision v0.15
- PyTorch v1.13.0 - torchvision v0.14
その他の詳細なリストは[こちら](https://github.com/pytorch/vision)をご覧ください。
ONNXのインストールとNumpyのダウングレード
以下の手順は、PyTorchモデルをTensorRTモデルに変換する場合にのみ必要です。
- Step 1. ONNXをインストールします。
pip3 install onnx
- Step 2. エラー修正のためにNumpyのバージョンをダウングレードします。
pip3 install numpy==1.20.3
資料
テクニカルサポートと製品に関するフォーラム
ご購入いただいた製品をスムーズにお使いいただけるよう、Seeedでは様々なサポートを提供しています。ご希望に合わせてコンタクトの方法をお選びください。
出典 : Seeed Studio資料 Wiki - Edge Computing https://wiki.seeedstudio.com/YOLOv8-TRT-Jetson/
*このガイドはSeeed Studioの許可を得て、スイッチサイエンスが翻訳しています。